Estimation of Importance of Web Pages for Web Crawlers
Priority Queue Based Estimation of Importance of Web Pages for Web Crawlers
Abstract-There are hundreds of new Web pages that areadded daily to Web directories. Web crawlers are developing over the same time of Web pages growing up rapidly. Thus, the need for an efficient Web crawler that deals with most of Web pages. Most of Web crawlers do not have the ability to visit and parse pages using URLs. In this study, a new Web crawler algorithm has been developed using priority queue. URLs, in crawled Web pages, have been divided into inter domain links and intra domain links. The algorithm sets weight to these hyperlinks according to type of links and stores links in the priority queue. Experimental results show that the developed algorithm gives a good crawled performance against unreached crawled Webpages. In addition, the developed algorithm has a good capability to eliminate duplicated URLs.
I. INTRODUCTION
Getting access through huge information around the world is becoming more important than ever [1]. Therefore, the importance of achieving the desired information in the right way will gradually increase in the upcoming years. In order to collect all/most of Web pages in the Internet, the need of Web robots occurred. It is becoming the most common tool used either to achieve certain Web pages or for gathering specific information from a Web page in any given subject.
A search engine is a tool used to search for content on the Internet with a specified user query. Search engines listed almost all of the Web sites in the world. These lists can be categorized, and provide a quick access to information that is asked by the users.
There are hundreds of new Web pages added daily to Web directories [2]. Academic researches show how it is very important to prioritize finding good or important pages and go through them in a fast way over discovering less important Web pages.
Web crawlers has the ability to visit all Web pages on the Internet to get classify and index the existing and new Web pages. The Web crawler agents simply send HTTP requests for Web pages that exist on other hosts. After HTTP connection, Web crawler starts to visit a specific connected Web page and extracts all hyperlinks or other contents of the Web page. Then, store its textual summarization in order to use after that for indexing the contents. The crawler then parses those Web pages to find new URLs.
Most of existed Web Crawlers agents do not have the ability to visit and parse Web pages. The reason is that the network bandwidth is very expensive [3]. Another reason is that there may be a limitation in storage where the crawler tries to store the data in a disk [4].
In this paper, a new Web crawler algorithm has been developed based on priority queue for estimate of importance of Web pages. In this work, URLs have been divided into two categories as intra links and inter links and weight is set for URLs according to their types.
II. RELATED WORKS
There are many Web crawler algorithms developed to manage Web sites. Fish algorithm is developed by De Bra et al. [5]. This algorithm works in a similar way of catching a fish. According to this approach, the group of fishes moves towards food. The group that is not near the food will die. Each crawler agent explores “feeder” areas which contain more “food”, i.e. relevant documents, and possibly “dry” directions with no relevant findings. Although fish algorithm is easy to apply, it has some limitations; connectivity-score distribution is given 1 to each connected node and gave 0 or 0.5 discrete calculations.
The Shark-Search method [6] suggests using Vector Space Model (VSM) [7] as a technique to select page priority from crawl candidate pages. To determine the value of a node, it will go into Webpage content, anchor text, the text surrounding the URLs and the priority mount for parent URLs. The difference between shark and fish algorithms is that shark algorithm uses fuzzy logic technique for distributing scores among the URLs while fish algorithm uses binary scoring to sort URLs. Another difference is that shark search algorithm uses Vector Space Model (VSM) for searching while fish search algorithm regular expressions for searching inside Web documents.
To determine high quality Web pages to crawl, Cho et al. [8], presents a new connectivity-based criteria using Breadth-first algorithm. Cho et al, uses four different algorithms (Breadth-first, backlink count, Page Rank, and Random algorithm) to crawl a single domain (Stanford.edu) Web site. The experimental results showed that to crawl a high page rank Web pages from the downloaded pages first before the other Web pages. A Partial Page Rank algorithm will be the best choice to get better results. The next best algorithm is Breadth-first, then Backlink-count will be fine to use as a Web crawler algorithm, besides, it is shown that to find high page rank Web pages, Breadth-first search algorithm will be the recommended to get better results.
Najork and Wiener have applied a real crawler over 328 million of Web pages [9]. To crawl Web pages Najork and Wiener suggest using the connectivity-based as criteria to get Webpages priority for crawling. As a result, they showed that the connectivity-based criterion is getting better results than other known criteria like popularity of pages and content analyzing. The reason is the connectivity-based criteria are easy to use and get fast results without needing extra information. As experimental results, Mercator [10] is used to crawl Web pages and download it and using Connectivity Server [11] in order to reach URLs faster inside downloaded Web pages.
Other research in Breath-first algorithm comes from Yates et al. [12]. They used Page Rank as criteria to test Breadth-first, Back link-count, Batch-Page Rank, Partial-Page Rank, OPIC and Larger-sites-first algorithms. The experimental results show that Breadth-first algorithm is a good strategy to get the first 20 %-30% of Web pages at the start crawling the Web. Depending to their results, the performance of Breadth-first algorithm will be lower after a couple of crawling days. This happens because of the large number of URLs of other pages that points to these Web pages, and then the quality average for crawled pages is getting down gradually day after day.
Abiteboul et al. [13] introduced OPIC (On-line Page Importance Computation) a new crawling strategy algorithm.
In OPIC, each page will give a value to start with “cash”. Then it is starting to distribute it equally to all pages it is pointing to and calculating all these months of “cash” to get the page score. Beside “cash” mount, there is another mount in OPIC algorithm named “history”. The mount of “history” is used as a memory of the pages, OPIC uses “history” mount to get the mount to the visits page from the start of crawling process to reach the last crawled page. Although OPIC algorithm is similar to Page Rank algorithm in calculating the score of each Web page, but it is faster and is done using single step. This done because OPIC crawling algorithm is downloading the pages with high cash mount. An OPIC crawling algorithm tries to download first pages in the crawling frontier with higher value of “cash”. According to the OPIC crawling algorithm, the Web pages may be downloaded several times depending on page issue and this will affect and increase crawling time.
Zareh Bidoki et al. introduces smart Crawling Algorithm depends on Reinforcement learning algorithm (FICA) [14]. In FICA crawling algorithm, the priority of crawling Webpages is depending on a concept named logarithmic distance between the links. The logarithmic distance between the links (Link-Connectivity) as criteria with a similarity to Breadth-first algorithm determines which Web page to be crawled next. FICA algorithm is using less resource with less complex to crawl Web pages and rank the Web pages while crawling it on-line. Zareh Bidoki et al. tries to develop FICA algorithm and purpose FICA+ [15] algorithm. FICA+ algorithm is derivate from the FICA algorithm by using of backlink calculation and the specification of Breadth-first search algorithm. Zareh Bidoki et al. used University of California, Berkeley as a database source to test their algorithms. The goal was to use a FICA+ algorithm with Breadth-first, Backlink count and Partial PageRank, OPIC and FICA algorithms. The other goal was to determine which algorithm is getting important Web pages with a higher PageRank first than the other pages. The result showed that
FICA+ got better results than the other crawling algorithms. C. Wang, et al. [16] introduced OTIE (On-Line Topical Importance Estimation) algorithm to manage the results and improve it from the frontier in the crawling process. The OTIE algorithm arranges the URLs inside the frontier by using a combination of Link-based and Content-based criteria analyzer. OTIE algorithm is a focused crawling algorithm that is used for general purpose. They used Apache Nutch [17] for easy implementation and test. There is similarity between OTIE algorithm and OPIC algorithm, the similarity is that OTIE contains “cash” that is transferred between Web pages as it is exist in OPIC algorithm. Depending on previous works [18, 19], Link-based method in a focused crawler algorithm gets low performance in downloading Web pages. To solve this issue they used bias, the cash mount distributes in OTIE in order to prefer on-topic
Webpages and to push down off-topic Webpages.
III. METHODOLOGY
According to the information obtained as a result of the literature, a successful Web crawler algorithm must parse all links found within a Web page. Besides the relationship between the links increases the strength of the crawling operation. The other element of a successful Web crawler algorithm design is to measure the importance of the link. To measure the link importance, the crawler will parse all the links from a given seed link and divide them into two kinds of links. Out-Link which is the link found in the extracted seed link and refers to other links outside the seed’s domain (Inter-Domain). In-Link is the link found in the extracted seed link and refers to the same domain which the seed URL belongs to (Intra-Domain). URL frontier is a data structure that contains all of the URLs intended to be downloaded. Most of Web crawler applications are using frontier Breadth-First with FIFO technique to select the URL seed to start crawling with.
In data structure concepts: FIFO technique happens when elements are removed from the rear end of the queue in order to insert elements into the front end of the queue. This issue is different and more complex in Web crawler. It starts sending a large number of HTTP requests to a server and this makes it a complex structure. In this context, to be held in parallel with multiple HTTP requests, it should not go back to the head of the queue rather than it should be done in a parallel way. To use this structure in a developed algorithm, a Priority Queue structure is proposed to work as a frontier of the developed Web crawler algorithm. All parsed URLs are placed inside Priority Queue according to their gained scores. The selection of a next seed URL will be determined according to the highest score received by the links.
To avoid parsed URLs to be waiting for long time inside developed Frontier, a time control mechanism has been developed. Time control mechanism will control URL waiting time inside Frontier in every new parsed URLs insertion process. Using this mechanism every URL inside Frontier will be wait for specific time to be crawled. If this URL reached this time it will be dropped from Frontier structure. Thus, to crawl a URL, it should be under the given specific time that be set as maximum waiting time otherwise it will be dropped from Frontier.
It is known that the number of URLs that exist in any seed URL is unknown. Taking a process with only one URL in each crawler process will slow up program performance. Therefore the need to use multi-threading process to speed up dequeue operation from developed frontier Priority Queue structure was very important issue.
|
LS |
( ) |
* |
(1) |
|
( ) |

Where LS is Link Score, α is the sum of Inter Link Size and Intra Link Size. β is the minimum value of link size between Inter Domain and Intra Domain links and θ is assigned weight for each category of links. Figure 2 shows the function of developed Web crawler algorithm and how it works.
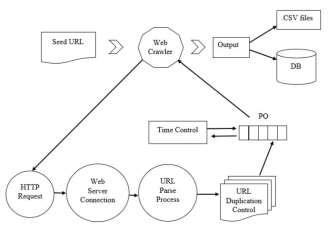
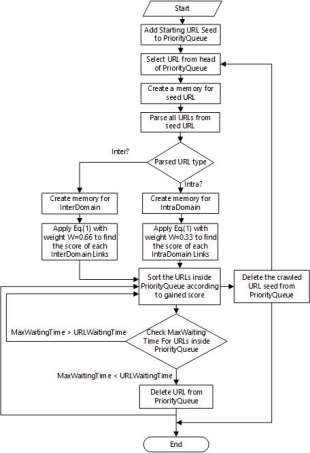
Fig. 1. The flowchart of developed Web crawler algorithm
The flowchart of developed Web crawler algorithm is given in figure 1. After selecting a Web page as seed URL, the crawler will clear unwanted tags and tries to categorize all URLs inside it into Intra Domain and Inter Domain. Intra Domain, is the group of links founded in the extracted seed link. It is refers to the same domain which the seed URL belongs to. Inter Domain is the group of links founded in the extracted seed link and refers to other links outside the seed’s domain. To measure the importance of each parsed Web page, they are all scored according to the type of the page.
In this work, the focus was on the outgoing links (Inter Domain) contained in a seed URL more than in-links (Intra Domain). The reason is to avoid link-loops inside on domain. It is believed that new links from different Web pages will lead us to non-stop crawling process and the algorithm will continue finding new domains to be crawled. Because of that, amount with 2/3 was given as a weight to Inter Domains’ link. In the same time a mount with 1/3 was given as weight to Intra Domain.
According to each category of links and its specification of each group of links, the general form of the equation (1) will be applied:
Fig. 2. The developed crawling algorithm and its functions
The pseudo code of the proposed crawling algorithm is shown in Algorithm 1. In the algorithm, PQ is the Priority Queue containing URLs parsed from seed URL. X refers to the weight mount of Inter domain and Intra domain, here X is selectable value for both of Inter and Intra domain weights. To determine the score of Inter domain0.66 is used as a value for X, and for Intra domain X=0.33. M, is the created memory for the seed URL to store the weights and record the scores. LS, is links’ score that can be applied to determine the score of each Inter and Intra domain links.

Algorithm 1: The pseudo code of the proposed crawling algorithm
According to figure 3, when the crawler starts to process seed URL (A), it is starting to parse its URLs. These URLs are: (B, C, D, E, F, G and H). Then start to categorize the URLs into Inter and Intra domains. Here five URLs (B, C, D, E and F) are Inter domain of seed (A) that refer to different domains, two URLs (G and H) are Intra domains for seed (A) that refer to the same seed URL domains. Now, regarding
Equation (1), to determine the Inter Domain Links Score
|
LS inter |
have the value of α which is as mentioned before is |
||||||
|
int er |
|||||||
|
the sum of Inter Link |
Size |
and Intra Link |
Size |
||||
|
int ra . Sinceint er |
int ra |
, then the value of |
int ra |
= |
|||
 2. Now to find the scores of each Inter Domain. Links follows use the value of =0.66 as following Equation (2):
2. Now to find the scores of each Inter Domain. Links follows use the value of =0.66 as following Equation (2):
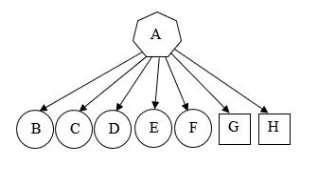
Fig. 3. Sample of Web crawler tree
|
LS inter |
( int er |
int ra) |
int ra |
* 0.66 |
(2) |
|
( int erint ra) |
|||||

Using the Equation (3) with changing the value of θ to 0.33, will help to find the score of Intra Domain Links:
|
LS intra |
( int er |
int ra |
) |
int ra |
* 0.33 |
(3) |
|
( int erint ra) |
||||||
A Priority Queue structure will be built at this stage. These URLs in the queue will be stored according to the gained score. Inside the priority queue structure, the URLs will be sorted descending from highest score URL to the lowest score. The next seed URL will be selected from the queue according to the highest URL score that exists in the tail of the queue. Every selected URLs will have amount of weight (W= 1) to start with. When crawler starts the process, the seed URL will be deleted and add the extracted URLs to the Priority Queue according to its gained score. The crawling process will not stop working until there are no more URLs found in the Priority Queue.
During crawling process, Priority Queue structures will be under control by developed the time control mechanism to examine all URLs waiting inside the Frontier. All scored URLs will be stored inside the Frontier with their insertion time. By the time the Frontier structure will be getting bigger. Thus, to avoid memory heap error, every URL will be dropped if it has reached the maximum waiting time while it has been waiting for its turn to be crawled. Therefore, crawling process will go through the Frontier and select next URL seed according to its score and waiting time properties. After parsing all its URLs, the selected seed URL will be deleted from the Frontier but will be kept by applied duplication control mechanism.
IV. EXPERIMENT RESULTS
According to literature research results, there are many URLs used to perform as different seeds during Web crawler process. In the developed Web crawler algorithm, http://www.stanford.edu isused as a dataset used in [8] too.Besides, http://www.wikipedia.org the world’s biggest online encyclopedia is used. The 3rd seed that was http://www.yok.gov.tr aTurkish governmental Website thatcontains important information about Turkish universities and also other Turkish governmental Websites.
After running the developed Web crawler algorithm, FIFO Queue techniques are used to select seeds from dataset to start the crawling process. Using Priority Queue techniques parsed URLs were sorted inside it according to the scores they have gained. With the similarity to FIFO techniques, the next URL seed will be selected from Priority Queue structure will be the URL that gained a higher score than other URLs. The number of URLs exist in any seed URL is unknown and dequeue only one URL each crawling process will slow up program performance, so multi-threading process is used to speed up the dequeue operation from developed frontier Priority Queue structure.
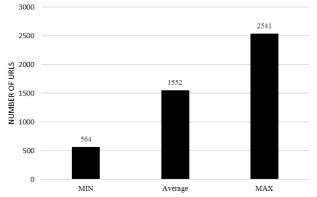
Fig. 4. MAX, Average and MIN crawled Webpages during crawling process
Overall, the number of URLs waiting at the frontier structure of the Web crawler application consists of hundreds of millions of URLs. Therefore, URLs must be saved to disk. The reason for assigning scores for parsing links is to make the developed algorithm to decide which link will be crawled earlier than other links.
As an experimental results, the maximum, average and minimum speed of crawled Webpages within a given time segment is demonstrated. Figure 4, shows the performance of developed crawling algorithm by getting the minimum, average and maximum number of crawled Webpages during crawling operation.
As shown in figure 4, there is uncrawled data during this experimental. The reason is that to crawl a given seed URL, the program will give a connection timeout to connect to the HTTP protocol, some Websites take time to respond to this HTTP connection requests and some of Websites will not respond to this request, besides, to crawl a Web page the program will load the whole content of a given page into memory before starting to parse it and extract its links. All these reasons can affect crawling speed performance.
 control mechanism, a single URL will be waiting inside Priority Queue structure for maximum 30 minutes. Regarding to developed mechanism the lowest score gained by parsed URLs will be dropped from Crawling Frontier to avoid filling the Queue without crawling.
control mechanism, a single URL will be waiting inside Priority Queue structure for maximum 30 minutes. Regarding to developed mechanism the lowest score gained by parsed URLs will be dropped from Crawling Frontier to avoid filling the Queue without crawling.
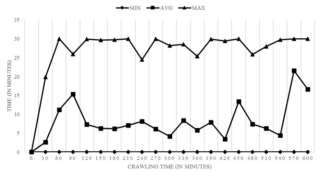
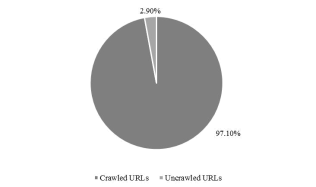
Fig. 5. Percentages of crawled Webpages vs. uncrawled Webpages
Figure 5 is showing the percentages of crawled Webpages is %97.10 of whole crawled Webpages while uncrawled Webpages forms %2.90 of the whole crawled Webpages during the crawling process for many reasons. Table I shows uncrawled Webpages errors’ types and their percentages.
TABLE I: GENERAL ERROR TYPES FOR UNCRAWLED URLS


|
Error Type |
Percentages |
|
404 |
%30.97 |
|
403 |
%19.67 |
|
503 |
%5.83 |
|
Other HTTP Status Codes |
%8.38 |
|
Unknown Supported MIME Type |
%21.68 |
|
Unknown Errors |
%10.75 |
|
Time Out Errors |
%2.73 |
To analyze uncrawled Webpages errors types in more details, error types has been divided into two parts. HTTP status types and other errors types. As shown in Table II, uncrawled Webpages error that comes from HTTP status types was %64.85 from total uncrawled URLs while %35.15 of total uncrawled URLs was coming from other errors types during crawling process.
TABLE II: ERROR TYPES FOR UNCRAWLED URLS


|
Error Type |
Percentages |
|
HTTP Status Codes |
%64.85 |
|
Other Errors |
%35.15 |
Analyzing HTTP status errors in more details table III shows that %47.75 HTTP status errors belongs to HTTP state error (404) %52.25 makes other HTTP error states.
TABLE III: HTTP STATUS ERROR CODE FOR UNCRAWLED WEBPAGES

|
HTTP Status Error |
Percentages |
|
404 |
%47.75 |
|
403 |
%30.34 |
|
503 |
%8.99 |
|
Other HTTP Status Codes |
%12.92 |
While this developed algorithm is depending on high priority to crawl URL links, figure 6 shows minimum, average and maximum time for waiting for a single link inside the Priority Queue.
Fig.6. MAX, Average and MIN waiting time inside Priority Queue every 30 minutes of crawling process
Figure 7 shows the number of URLs that had been dropped. The number of dropped URLs after 30 minutes from the start of crawling process are more than other time duration. The reason is that the developed Priority Queue control mechanism starts after 30 minutes from crawling process. Thus the waiting URLs inside Priority Queue will get its normal forum after the 60th minute from the start of crawling process. Using the developed time control mechanism, every URL will be checked to measure its waiting time inside Frontier. This new mechanism will be activated every time a new parsed URL passes inside Frontier structure.
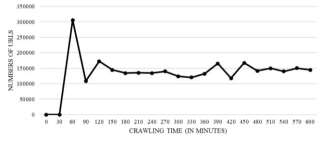
Fig. 7. The minimum, average and maximum dropped URLs from Priority Queue
By using the developed time control mechanism, the URLs will not be kept more than a specific time inside the Priority Queue. The URLs that had waiting more than the specific time inside the Priority Queue will be dropped. Regarding this mechanism, the maximum waiting to time for any URL will be under the specific time that has been set in time control mechanism.
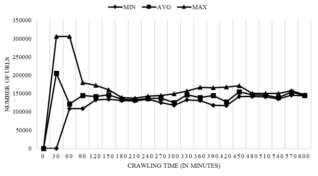
Fig. 8. Fill of Priority Queue during crawling process
Figure 8 show that there are more 300000 URLs inside the Priority Queue in the first 60 minutes from the start of crawling process. But regarding to the developed time control mechanism, the Priority Queue structure is getting to be more stable and optimize the URLs inside it (100000-200000 URLs) during crawling process.
Queue’s contents of Inter and Intra domain links for every 30 minutes of crawling process.
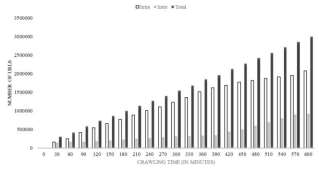
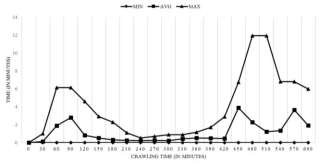
Fig. 9. MAX, Average and MIN speed of crawling during crawling process
To measure the speed of crawling process, an analyze of minimum, average and maximum crawling speed has been done. Figure 9 shows the speed of crawled Webpages, for the given 30 minutes of crawling time. This speed is referring to the time needed to parse all URLs from current seed.
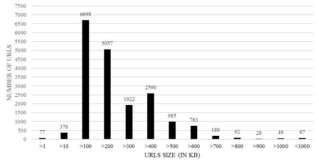
Fig. 10. Size of crawled Webpages
The time duration (240-360 minutes) of crawling process shows the maximum time between 1 to 1.5 minutes needs to parse all URLs from current parent URL. While in the 480th minute of crawling process, the maximum time is 12 minutes needed to parse all URLs from current parent URL. The reason for that difference is that the parent URL (seed URL) in time duration (240-360 minutes) contains less child URLs (parsed URLs) so the crawling speed will be faster than the parent URL that contains more child URLs (parsed URLs) and leads to slowness in the crawling speed.
Another factor that could be effecting crawling process speed is Webpages size. Figure 10 shows that although the maximum size of crawled Webpages was 100 KB but there were Webpages with size 500 KB too. As a result, getting bigger Webpage size leads to slowness in crawling process.
In this developed Web crawler algorithm as mentioned before, more attention was given to develop a crawler algorithm with Inter Domain URL. The reason for that is to avoid link-loops inside domain and that new links from different Web pages will lead us to non-stop crawling process and the algorithm will continue to find new domains to be crawled. Because of that, assigned 2/3 of seed URL’s weight was assigned to Inter Domains’ links and 1/3 of given weight was assigned to Intra Domain. Figure 11 shows Priority
|
Fig. 11. Size of crawled Webpages |
||||
|
TABLE IV: MOST VIEWED COUNTRY‘S DOMAIN NAME DISTRIBUTIONS |
||||
|
Domain Name |
Percentages |
|||
|
.ca |
49.25% |
|||
|
.uk |
16.84% |
|||
|
.it |
7.46% |
|||
|
.be |
5.61% |
|||
|
.tr |
4.83% |
|||
|
.de |
3.41% |
|||
|
.nz |
2.63% |
|||
|
.jp |
1.49% |
|||
|
.gl |
1.07% |
|||
|
.bg |
0.92% |
|||
|
Others |
6.47% |
|||
After separating these Webpages to domain names, the most crawled domain name distribution was determined. Table IV shows the most viewed country’s domain name distribution.
The table shows that although the crawling process starts with .edu, .org and .gov domain names, but during crawling process the most crawled Webpages was country domain name like .ca Canada, .UK United Kingdom and .it Italy.
From total crawled Webpages as shown in table V the most crawled domain name was .com extension. According to developed Web crawler algorithm, giving Inter domain URLs more importance to be crawled over Intra domain URLs lead the crawling process to crawl new Webpages from different domains.
TABLE V: MOST CRAWLED DOMAIN NAME

|
Domain Name |
Percentages |
|
.com |
95.23% |
|
.jobs |
2.29% |
|
.org |
1.69% |
|
.net |
0.43% |
|
.net |
0.12% |
|
.info |
0.11% |
|
other |
0.12% |
The Webpages on the Internet are connected to each other. While some of Webpages are connected to new Webpages, new Webpages that are pointing (connecting) to the same
Webpages will appear, leading to duplication in Webpages, which means these Webpages were already visited/crawled before.
Figure 12 shows the duplication of URLs that had been detected in crawling process for each 30 minutes. To avoid URL duplication while crawling process, a duplication control process starts inside the Priority Queue to check whether the URL was processed before or not by using the advantage of Linked Hash Set inside it. Using Linked Hash Set as a control gate will double check the parsed URLs before adding them to the Priority Queue structure to see while it’s crawled before or not. If the candidate parsed URL was not crawled before, then the URL will be added to the Priority Queue, hence waiting its turn according to their scores.
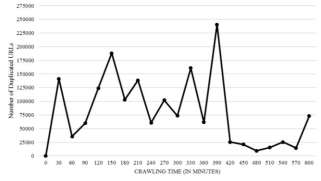
Fig. 12. Duplicated URLs counts for every 30 minutes of crawling process.
V. CONCLUSIONS
In this study, a new algorithm has been introduced to crawl Web pages. The developed algorithm is based on using priority queue as seed frontier and dividing crawled URLs into inter and intra links. The developed algorithm focuses on adding crawled inter domain links to the frontier more than focusing on intra domain links. The reason for that is to avoid link-loops inside a domain. As a result, this leads to discover new links on different hosts and domains. The experimental results show that the developed crawler algorithm gives a good crawled performance against to unreached crawled Webpages. Besides the developed algorithm also has the capability to eliminate duplicate URLs.
REFERENCES
- S. Brin, and L. Page, “The anatomy of a large-scale hypertextual Web search engine,” Computer Networks and ISDN Systems, vol. 30, pp.107-117, 1998.
- D. Lewandowski, “A three-year study on the freshness of Web search engine databases,” Journal of Information Science vol. 34, pp. 817-831, 2008.
- H. Ali, “Effective Web Crawlers,”. PhD. dissertation thesis, School of
Computer Science and Information Technology, Science, Engineering, and Technology Portfolio, RMIT Univ., Melbourne, Victoria, 2008.
- J. Cho, “Crawling the Web: discovery and maintenance of large-scale Web data,” PhD. Dissertation thesis, Dep. of Computer Science,
Stanford University, 2001.
- P. De Bra, G. Houben, Y. Kornatzky, and R. Post, “Information retrieval in distributed hypertexts,” Proceedings of RIAO’94, Intelligent Multimedia, Information Retrieval Systems and Management, pp. 481-491, 1994.
- M. Hersovici, M. Jacovi, Y. S. Maarek, D. Pelleg, M. Shtalhaim and S. Ur, “The shark-search algorithm. An application: tailored Web site mapping,” Computer Networks and ISDN Systems, vol. 30, pp. 317-326, 1998.
- G. Salton, A. Wong and C. Yang, “A vector space model for automatic indexing,” Communications of the ACM, vol. 18, pp. 613-620, 1975.
- J. Cho, H. G. Molina, and L. Page, “Efficient crawling through url ordering,” Computer Networks and ISDN Systems, vol. 30, pp. 161-172, 1998.
- M. Najork, and J. L. Wiener, “Breadth-first crawling yields high-quality pages,” In Proceedings of the 10th international conference on World Wide Web ACM, pp. 114-118, 2001.
- A. Heydon, and M. Najork, “Mercator: A scalable, extensible Web crawler,” World Wide Web, Springer, vol. 2, pp. 219-229, 1999.
- K. Bharat, A. Broder, M. Henzinger, P. Kumar and S. Venkatasubramanian, “The connectivity server: Fast access to linkage information on the Web,” Computer networks and ISDN Systems, vol. 30, pp. 469-477, 1998.
- R. Baeza-Yates, C. Castillo, M. Marin and A. Rodriguez, “Crawling a country: better strategies than breadth-first for Web page ordering,”
InSpecial interest tracks and posters of the 14th international conference on World Wide Web, ACM, pp. 864-872. 2005.
- S. Abiteboul, M. Preda, and G. Cobena, “Adaptive on-line page importance computation,” InProceedings of the 12th international conference on World Wide Web, ACM, pp. 280-290, 2003.
- A. M. Z. Bidoki, N. Yazdani and P. Ghodsnia, “FICA: A novel intelligent crawling algorithm based on reinforcement learning,” Web Intelligence and Agent Systems : An International Journal, vol. 7, pp.363-373, 2009.
- M. A. Golshani, V. Derhami and A. ZarehBidoki, “A novel crawling algorithm for Web pages,” InInformation Retrieval Technology, Springer Berlin Heidelberg, pp. 263-272, 2011.
- C. Wang, Z. Y. Guan, C. Chen, J. J. Bu, J. F. Wang and H. Z. Lin, “On-line topical importance estimation: an effective focused crawling algorithm combining link and content analysis,” Journal of Zhejiang University-Science A, vol. 10, pp. 1114-1124, 2009.
- Nutch, Apache. http://nutch. apache.Org (2015).
- F. Menczer, G. Pant, P. Srinivasan and M. E. Ruiz, “Evaluating topic-driven Web crawlers,” InProceedings of the 24th annual international ACM SIGIR conference on Research and development in information retrieval, ACM, pp. 241-249, 2001.
- M. Chau and H. Chen, “Comparison of three vertical search spiders,” Computer, vol. 36, pp. 56-62, 2003.
- S. Chen, B. Mulgrew and P. M. Grant, “A clustering technique for digital communications channel equalization using radial basis function networks,” IEEE Trans. on Neural Networks, vol. 4, pp. 570-578, 1993.
- J. U. Duncombe, “Infrared navigation-Part I: An assessment of feasibility,” IEEE Trans. Electron Devices, vol. ED-11, pp. 34-39, 1959.
- C. Y. Lin, M. Wu, J. A. Bloom, I. J. Cox, and M. Miller, “Rotation, scale, and translation resilient public watermarking for images,” IEEE Trans. Image Process., vol. 10, pp. 767-782, 2001.

Mohammed Rashad Baker Received the BS degreein Sofware Engineering Techniques from Collage of Technology – Kirkuk, Iraq in 2005. He received MSc degree in Computer Engineering from Gazi University-Ankara, Turkey. In 2009 and currently he is PhD candidate at Gazi University Faculty of Engineering Department of Computer Engineering. His research interests include Web Mining, Web Crawler and Web Ranking, Web and Mobil Wireless Mesh Networks, Wireless Network Routing
Protocols.
M. Ali Akcayol received the BS degree inElectronics and Computer Systems Education from Gazi University in 1993. He received MSc and PhD degree in Institute of Science and Technology from Gazi University – Ankara, Turkey in 1998 and 2001, respectively. His research interests include Mobile Wireless Networking, Web Technologies, Web Mining, BigData, Cloud Computing, Artificial Intelligence, Intelligent Optimization Techniques and
 Hybrid Intelligent Systems.
Hybrid Intelligent Systems.