Hierarchical Dirichlet Process and Strategic Management
The Utility of Hierarchical Dirichlet Process for Relationship Detection of Latent Constructs
  ABSTRACT
This paper introduces Hierarchical Dirichlet Process (HDP) as an effective method to advance strategic management research. We use HDP to automatically explore large collections of text in a stream of literature for the purpose of knowledge and hypothesis generation. This method analyzes the words of the original texts to identify latent constructs, and detect their underlying relationships. We illustrate detailed application of HDP on one of the most important areas of strategic management (i.e. absorptive capacity), and conclude the effectiveness of this method in relationship detection of the constructs, and generation of novel hypotheses.
Keywords: Hierarchical Dirichlet Process, Topic modeling, Exploratory studies, Hypothesis generation
INTRODUCTION
This study is the first to focus on the use of Hierarchical Dirichlet Process (HDP) (Teh, Jordan, Beal, & Blei, 2004a) in text mining to detect latent constructs and their underlying relationship in strategic management. The process of knowledge generation is often associated with high degree equivocality and uncertainty (Li, Lin, Huang, & Crossland, 2016). Especially, it is time consuming when scholars are required to review a large volume of studies to hypothesize new relationships among constructs based on accumulated knowledge in a field. We demonstrate how HDP-based topic modeling can help automatically identify latent constructs that appear together in a specific stream of literature in strategic management. This specifically helps researchers ask the best questions based on co-occurrence and relationships of constructs that are captured through HDP. This paper uses HDP to advance knowledge generation in strategic management by employing textual analysis of electronic archives.
According to Popper (1959), the first step to generate novel knowledge is developing hypotheses. Hypothesis can be defined as falsifiable statements among two or more variables (Popper 1959). To generate hypotheses and advance literature, a number of approaches can be taken. Most importantly, one might engage in deductive (Kuhn, 1996) or inductive (Kilduff, 2006) research development. In other words, a researcher might begin with a theory and elicit hypotheses based on that theory or on the other hand, might attempt to develop theories based on real data and observations. Strategic management researches mainly focus on using deductive approaches in order to test hypotheses (i.e. to answer questions). To this point, there are very few works that focus on inductive approaches to generate new hypotheses (i.e. to ask questions). Greckhamer, Misangyi, Elms and Lacey (2008) and Li et al. (2016) proposed analytical approaches namely qualitative comparative analysis (QCA) and sparse inverse covariance estimation (SICE) in order to generate new hypotheses by the analysis of firm-level quantitative data.
However, there is not much systematic work done in strategic management to generate novel hypotheses by the analysis of accumulated knowledge in the form of textual archives. A naïve approach is that scholars should manually review all the documents in the archive to identify constructs that routinely materialize together. The ardor of reviewing voluminous studies is significant when hypothesizing relationships among emergent constructs. This paper addresses this challenge by introducing HDP-based topic modeling to strategic management field. HDP allows the strategic researchers to automatically identify constructs in a field of interest by the analysis of the observed words in the original texts. We further propose an analytical approach based on the outcomes of HDP to detect intrinsic relationships among constructs and generate new hypotheses. In the following sections, we describe HDP-based topic modeling method and its utilities. We further, provide an example of applying HDP in strategic management field.
METHODS
Topic Modeling
Topic modeling has been applied to organize, summarize, and understand large volume of documents including emails (Blei & Lafferty, 2009), scientific abstracts (Griffiths & Steyvers, 2004), and newspaper archives (Wei & Croft, 2006). It is a powerful technique to discover useful latent structure in unstructured textual data. In this paper topic modeling is used as a novel method to identify latent constructs and their underlying relationships from accumulated knowledge in a stream of literature, which is typically embodied in a collection of large volume of documents. The intuition behind our proposed method is the following: topic modeling algorithms analyze the patterns of word use in a collection of documents and extract the latent topics based on those patterns. Also, the weight of topics in each document is inferred as output of the algorithm. Then the latent constructs can be identified by reviewing the extracted topics, and the relationships among constructs can be captured based on an aggregated analysis of the topics having significant weight in each document.
This paper is not the first to use topic modeling in strategic management. Kaplan and Vakili (2015) utilized this technique as a way to create a new measure of novelty by identifying the patents that were originators of each topic. There are various topic modeling algorithms reported in the literature, each with their own advantages and limitations. Kaplan and Vakili (2015) used latent Dirichlet allocation (LDA) which is a simple yet powerful tool for discovering the hidden topical structure in large archives of text. However, LDA has been extended in many ways, resulting into more effective computational tools for topic modeling implementations. One of the main limitations of LDA is that it assumes the number of topics is known and fixed (Blei, Ng, & Jordan, 2003). Typically researchers determine the number of topics for LDA by conducting cross validation analysis (Blei, 2012). This requires tedious trial and errors on the number of topics to determine the one delivering the most semantically meaningful topics. An elegant solution to this limitation was proposed by Teh et al. (2004a) via developing a nonparametric Bayesian topic model known as hierarchical Dirichlet process (HDP). The “nonparametric” term in this algorithm can be understood as implying that the number of topics is unrestricted as opposed to LDA, namely, it is a random variable which will be estimated from the data.
In this paper, HDP is used as the underlying computational tool for implementation of topic modeling due to its superior advantage over LDA. In order to avoid too much technicality in the context of the paper, the detailed introduction of HDP is skipped. However, a simple introduction is provided to conceptually illustrate the utility of HDP-based topic modeling for detecting latent constructs.
Hierarchical Dirichlet Process
HDP is a Bayesian nonparametric technique, which allows researchers to automatically extract the latent topics from a collection of documents and identify the weight of the topics in each document. The basic idea is that each document is generated as a mixture of latent topics, where each topic is characterized by a distribution over the words, and the topic proportions vary from document to document. As opposed to LDA, the number of topics is not known in HDP and is to be inferred from the observable data. The nonparametric nature of HDP reposed on Dirichlet process enables the automatic inference of the latent topical structure including the topics, the number of topics exhibited in a collection, and the proportion of each topic in each document[1]. The underlying generative process of HDP is illustrated in Figure 1.
———————————————–
Insert Figure 1 about here
———————————————–
The shaded circles represent the observable random variables (i.e. 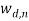 which denotes the
which denotes the 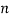 -th word in the
-th word in the 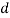 -th document). The unshaded circles are the latent (unobservable) random variables, namely, global set of topics to be used in the collection
-th document). The unshaded circles are the latent (unobservable) random variables, namely, global set of topics to be used in the collection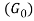 , specific subset of topics to be used in document (
, specific subset of topics to be used in document (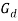 ), and the specific topic distribution over the words in the collection
), and the specific topic distribution over the words in the collection 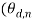 ). The boxes represent the plate notations used to illustrate the replications, i.e.
). The boxes represent the plate notations used to illustrate the replications, i.e. 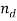 plate denotes the number of words within document
plate denotes the number of words within document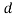 . The parameter
. The parameter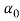 is used in and
is used in and 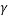 and H are used in
and H are used in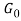 . The arrows indicate conditional dependencies among the variables in the following: given an underlying distribution H on multinomial probability vectors, a random distribution
. The arrows indicate conditional dependencies among the variables in the following: given an underlying distribution H on multinomial probability vectors, a random distribution 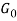 is selected from Dirichlet process
is selected from Dirichlet process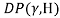 . Then for each document (
. Then for each document (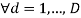 ) is sampled from Dirichlet process
) is sampled from Dirichlet process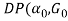 )[2]. From
)[2]. From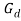 multinomial probability vectors
multinomial probability vectors 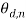 are repeatedly sampled. Finally the words
are repeatedly sampled. Finally the words  are sampled from a multinomial distribution with probabilities
are sampled from a multinomial distribution with probabilities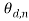 . The HDP algorithm infers the above random variables by computing the posterior distribution of the latent variables in the documents using Markov Chain Monte Carlo (MCMC) techniques such as Gibbs sampling (for more details please refer to the paper by Teh, Jordan, Beal, & Blei (2004b)).
. The HDP algorithm infers the above random variables by computing the posterior distribution of the latent variables in the documents using Markov Chain Monte Carlo (MCMC) techniques such as Gibbs sampling (for more details please refer to the paper by Teh, Jordan, Beal, & Blei (2004b)).
Given a collection of documents, HDP delivers two outcomes, namely, (1) a list of topics where each topic is represented as a sequence of words weighted by their importance in that topic, (2) a list of documents where each document is represented as a mixture of topics weighted by their importance to that document. The outcomes of HDP can be adopted to identify latent constructs and their underlying relationships from accumulated knowledge in a stream of literature (i.e. documents). The utilities of HDP-based topic modeling in relationship identification and hypothesis generation are discussed in the subsequent section.
Utilities of HDP-based Topic Modeling
The first benefit of HDP-based topic modeling is that it can be applied as an exploratory technique. It is used to automatically explore large document collections, and extract the latent topics from the analysis of the documents. The extracted topics can help researchers discover existing or even novel (unexpected) constructs from the collections. The main idea is that based on the co-occurrence of the words in the documents, HDP-based topic modeling effectively extracts the topics which are specified as multinomial distributions over the recurring words.
Using HDP, researchers are able to allow the constructs to emerge automatically from the data, instead of reviewing the documents manually that could be very time consuming and frustrating. This is particularly useful in case of emerging fields where equivocality breeds a wide diversity of perspectives and definitions. Hence, the findings of HDP can lead to the identification of latent constructs that are certainly helpful to motivate generation of novel hypotheses. However, it should be emphasized that this approach is not an alternative to the existing knowledge generation techniques. Rather, it is seen as a systematic and complementary approach for researchers to identify constructs that exhibit material relationships based on existing knowledge.
The second benefit of HDP is that it can be used to identify relationships among individual pairs of constructs. The outputs of HDP can be analytically treated to detect the relationships. To be specific, the HDP decomposes each document into a mixture of constructs where each construct has a different weight to the document. For each document, the constructs with significant weights are selected (for example in our case top 3 constructs could be adequate to summarize the content of the abstracts). Then the frequency of each pair of constructs that appear together across all the documents is counted and represented in a matrix format (i.e. adjacency matrix[3]). This idea is presented schematically in Figure 2.
———————————————–
Insert Figure 2 about here
———————————————–
In Figure 2 (a) the boxes represent each document (in this example there are 10 documents in the collection) and the circles represent top 3 constructs selected in each document (in this example there are totally 6 constructs learned from this collection). The adjacency matrix of the relationships between the constructs is presented in Figure 2 (b). The vertical and horizontal axes in the matrix represent the constructs. The diagonal elements in the matrix indicates the frequency of each individual construct across the documents. For example in this matrix construct 2 appears with frequency of 7 which is the highest frequency among all other constructs in the collection. The non-diagonal elements of the matrix show the frequency of each pair of constructs that appears in the collection. For example in this matrix the pair of constructs (1,2) appears seven times, and the pairs of (1,3), (1,6), (2,3), (2,6) appear 6 times, which are among the pairs with highest frequencies in the collection.
Based on the frequency of the non-diagonal elements three color codes red, blue, and white are used for better illustration of three levels of frequency, namely, high, medium, and low (or none), respectively. Identifying these levels can be done based on the distribution of the frequencies in the collection. For example, the frequencies in the first quartile, and in the second and the third quartile, and in the last quartile can be viewed as low, medium, and high levels respectively. The color codes allows the user to easily pin point and identify the pairs having higher relationships[4]. For example the corresponding elements in the adjacency matrix to the above pairs are filled with red color code.
The proposed adjacency matrix can be used as an effective tool to investigate what pairs of constructs are potentially correlated. In other words, the pairs whose corresponding elements in the adjacency matrix have high frequencies (i.e. filled with red or blue color codes) are probably more related than other pairs with lower frequencies (filled with white color code).
CASE STUDY- APPLICATION OF TOPIC MODELING
Sample
We have chosen absorptive capacity (AC) as the narrow area of interest, in order to apply our proposed method to an area in strategic management field. Cohen and Levinthal (1990) were the first scholars introducing AC to strategic management. Since then, this paper has been cited largely by scholars, as it can be seen by 31385 google scholar citation as of January 2017. The exponential increase of the citations, makes this area a potential knowledge domain for us to apply HDP-based topic modeling. As the original paper on AC was published in 1990, we searched for studies from 1990 forward. In order to search papers citing AC, we searched in EBSCO database for papers that have “absorptive capacity” in the tile, abstract or keywords. We also manually searched for papers in journals that were not included in the database yet. Also, in order to overcome publication bias or file drawer problem (Rosenthal 1979), we searched for dissertations and conference papers in academy of management proceedings. We only included abstracts of studies in our analysis. Usually, abstract of a paper gives sufficient information on what constructs are of interest in the study. This is consistent with other topic modeling papers in other areas (Teh et al., 2004a). Thoroughly searching the literature, we were able to have access to 1182 journal paper abstracts, 147 conference paper abstracts and 279 dissertation abstracts.
In the following section, the utility of HDP is demonstrated on our collection of abstracts. Phase I presents the extracted constructs from the collection. Phase II illustrates how HDP allows researchers to identify inherent relationships among the constructs extracted in Phase I.
Phase I: Identifying Latent Constructs in the Domain
In this phase, we apply HDP to extract the latent constructs from our collection. Before implementing HDP-based topic modeling, standard preprocessing techniques that are very common in text mining should be utilized to prepare the data (Feldman & Sanger 2007). Typically, text data is noisy and unstructured; hence, data preprocessing provides a consistent format for the data, and removes non-critical words that are not contributing to the analysis. To do that, we removed a standard list of stop words from the collection. Stop words refer to the common words in the language such as “is”, “was”, “we”, etc. In addition, the words that appear less than five times in the collection were removed. The above preprocessing procedures enable us to focus our analysis on the informative words of the collection.
Both data preprocessing tasks and HDP analysis were conducted in Python. The nltk library (Joakim, 2012) was used to preprocess the collection of abstracts. Then the gensim python library (Gensim Python software library) was utilized for conducting HDP analysis. The gensim package requires initial values for the HDP parameters, namely,, 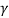 and H. Similar to the best practices of HDP in the literature (Teh et al., 2004b), the concentration parameters were sampled from gamma distributions, namely,
and H. Similar to the best practices of HDP in the literature (Teh et al., 2004b), the concentration parameters were sampled from gamma distributions, namely,  andÂ
and 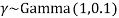 . Additionally, a symmetric Dirichlet distribution with parameters of 0.5 was used as a prior for base distribution H.
. Additionally, a symmetric Dirichlet distribution with parameters of 0.5 was used as a prior for base distribution H.
Applying HDP, 100 topics were extracted, among which 83 topics were semantically meaningful. Similar to other studies in the literature (Teh et al., 2004a), we excluded not meaningful topics from our results. Our final sets of topics include a wide range of constructs that have been used in the AC literature. In order to make sense of the output and have a clearer understanding of the results, similar to Song, Gnyawali, Srivastava & Asgari (2017) we considered three main categories to classify the constructs: (1) antecedents of AC, (2) outcomes of AC and (3) relational and contextual characteristics of the studies that used AC. Constructs that do not match with any of these categories have been grouped as “Others” in Table 1. The summary of the extracted constructs and their corresponding categories are presented in Table 1.
———————————————–
Insert Table 1 about here
———————————————–
Our first category refers to antecedents of AC. Prior literature has identified constructs relating to different kinds of knowledge and capability as antecedents of AC (Jansen, Van Den Bosch, & Volberda, 2005; Minbaeva, Pedersen, Björkman, Fey, & Park, 2003; Narasimhan, Rajiv, & Dutta, 2006). Thus, we grouped constructs related to knowledge and capability into antecedent category. For example, this category includes R&D capability, technological opportunity, ties diversity, integrated information technology capability, socialization capability, multinational corporations (MNC) subsidiary effort intensity, appropriability, marketing capability and human resources management (HRM) practices. Our results are pretty consistent with the current literature on antecedents of AC (Jansen et al., 2005; Setia & Patel, 2013; Minbaeva et al., 2003; Cohen & Levinthal, 1990; Tortoriello, 2014; Narasimhan et al., 2006).
The second category refers to outcomes of AC. To make a finer grained classification on outcomes, following Song et al. (2017), we categorized outcomes of AC into three sub-categories namely innovation outcomes, learning outcomes and firm performance outcomes. For example, innovation outcomes include product and process innovation, radical and incremental innovation, new product development speed, regional innovation and open innovation. Learning outcomes consist of constructs such as inter-organizational learning, cross-cultural learning and technology transfer. Diversification and international performance, long term and short term performance and firm growth are among the constructs in the sub-category of firm performance. Our findings are consistent with the literature on AC outcomes (Lane and Lubatkin, 1998; Tsai, 2001; Tsai, 2009; Fabrizio, 2009; Rothaermel and Alexandre, 2009; Patel, Kohtamäki, Parida, & Wincent, 2015).
AC has been appeared in numerous contexts with different relational characteristics and levels of analysis in the literature (Song et al., 2017). It would be interesting to investigate what constructs are related to the above settings. Hence, the third category of constructs includes relational and contextual characteristics of the studies where AC has been used. The constructs on relational characteristics contain, to name a few, mergers and acquisitions, alliances, small and medium sized enterprises, and multinational corporations. Individual, group, firm and region are the levels of analysis appeared in our extracted topics. Also, based on our results, international context, emerging market and high-tech are examples of the contexts where AC has been used. In the next phase, we explore inherent relationships among extracted constructs in this phase.
Phase II: Exploring Relationships among Constructs
Previous literature has applied AC in heterogeneous contexts, and found relationships with different antecedents and outcomes. Applying HDP not only brings insight on the main constructs used in the literature, but also it can reveal inherent relationships among them. Applying HDP, we expect to both uncover the existing relationships among the constructs in the literature, and reveal unexplored relationships that pave the way to creation of new hypotheses.
In this phase, we created adjacency matrix as explained in the methodology section. After creating the matrix, we were able to identify relationships between individual pairs of constructs. Three levels of correlations were detected based on the magnitude of the frequency. As it can be seen in Figure 3, the red squares correspond to pairs of constructs with the highest correlation. The blue squares represent medium level of correlation, and the white area shows no or very low correlation among constructs. Several notable relationships can be inferred from Figure 3. Consistent with the literature, we found that constructs representing AC have the highest correlations with innovation outcomes, learning outcomes and firm performance. These variables have previously been used as outcomes of AC in the literature (Lane and Lubatkin, 1998; Tsai, 2001; Patel et al., 2015). Most specifically, AC has the highest correlation with product innovation, followed by inter-organizational learning and firm growth. In addition, it can be observed that AC has a moderate relationship with value creation.
———————————————–
Insert Figure 3 about here
———————————————–
Variables that have been used as antecedents of AC, mostly have moderate relationships. The only variable among antecedents that has high relationship with AC is R&D capability. This is consistent with the results of prior literature that studied R&D and its effect on AC (Narasimhan et al., 2006). At the group level, AC has moderate relationship with group aspiration. Also, at firm level, it has moderate relationships with a number of constructs including manufacturing capability, technological opportunity, communication and socialization capability, patent stock and HRM practices. These relationships are consistent with results of prior literature (Cohen & Levinthal, 1990; Minbaeva et al., 2003; Jansen et al., 2005).
On the other hand, there are other correlations that can be used as a basis for generation of novel hypotheses. These correlations can show inherent relationships among constructs. For instance, Ac has moderate relationships with a range of constructs such as offshoring capability, change and initiation capability, conflict management capability and dynamic capabilities. Using these relationships, one possible hypothesis might be “Initiation and change capability is associated with firm’s absorptive capacity”. Then, researchers can develop a theoretical explanation on this, and test the hypotheses through data collection.
In addition to correlations between AC and different antecedents and outcomes, there are other sets of constructs that have inherent relationships. For instance, R&D capability has high correlation with patent stock of firms. This is completely consistent with current literature (Narasimhan et al., 2006). Similarly there are other pairs of constructs that are related based on our analysis. The most important ones are as follows: open innovation and firm growth, product innovation and operational capability, operational capability and outsourcing capability, operational capability and R&D, technological opportunity and outsourcing capability, marketing capability and ties diversity, offshoring and foreign spillover, ties diversity and product innovation, initiation and change capability and firm growth, group aspiration and dynamic capabilities. A number of these relationships that have not been addressed in the literature (e.g. operational capability and R&D, or group aspiration and dynamic capability) can bring insight for enthusiastic researchers and provide the basis for hypothesis generation.
DISCUSSION
In this paper, we introduced HDP-based topic modeling as a new method to advance hypothesis generation in strategic management. This method provides scholars with an analytical technique to analyze knowledge stocks in the form of textual archives. HDP is used to identify latent constructs in the field of interest and detect inherent relationships among the constructs. These relationships can then be used by the strategic researchers to generate novel hypotheses. We provided a detailed application of the proposed method to one of the emerging areas in strategic management -i.e. absorptive capacity. The main advantage of the proposed method can be seen in dealing with a large volume of studies. Specifically, using HDP, researchers can allow the constructs to emerge automatically from the data, instead of reviewing the documents manually that is time consuming and frustrating.
This paper offers different avenues for future research. Although this paper specifically focuses on strategic management, it also has implications for other fields of business management. This method can be applied both within a stream of literature and between streams of literature. It can be used as a bridge between different fields of management (e.g. entrepreneurship, human resources, strategic management) and provide insights by relating topics from distinct streams of research. Especially, where there is some overlap between fields, it would be interesting to discover how these fields have evolved and interacted over time, and what hypotheses can be generated based on the relationships among constructs. For instance, human resources scholars have a very large number of studies on recruitment and selection which take heterogeneous perspectives on most important predictors of firms’ outcomes (e.g. Behling, 1998; Joseph & Newman, 2010). On the other hand, strategic management researchers deal with a great number of predictors of firms’ outcomes and various moderators of these relationships. Taking these two streams of research, scholars have to deal with a large number of studies and constructs. Exponential increase in availability of scholarly work to researchers makes them focus on a very narrow stream of studies, and also focus on a couple of top tier papers, makes them overlook the bigger picture. However, using topic modeling shift the scholars’ attention to inherent relationships taking a wider perspective. Topic modeling is particularly useful today more than any other time with voluminous scholarly work.
[1] The Dirichlet process 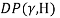 is a distribution over distribution. It has two parameters, a scaling parameter
is a distribution over distribution. It has two parameters, a scaling parameter 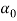 > 0 and a base probability distribution. Regardless of whether is continuous or discrete, a draw from Dirichlet Process (DP) is discrete with probability one. The discrete nature of DP makes it suitable to be used as a prior on mixture components (i.e. topics in this scenario), as each component can be associated to each atom in DP.
> 0 and a base probability distribution. Regardless of whether is continuous or discrete, a draw from Dirichlet Process (DP) is discrete with probability one. The discrete nature of DP makes it suitable to be used as a prior on mixture components (i.e. topics in this scenario), as each component can be associated to each atom in DP.
[2] The fact that is discrete (atomic) plays an important role in ensuring that the topics are shared across different documents. As is used as a base distribution for, then the atoms of are also samples from . Hence, topics selected in are always a subset of global set of topics in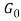 .
.
[3] Adjacency matrix is a symmetric matrix used in graph theory to represent the relationship between nodes (West, 2001).
[4] The diagonal elements are filled with white color code, as they represent the relationship of each construct with itself and therefore has no meaning.