Internet of Things Paradigm
Introduction
According to 2016 statistical forecast, there are almost 4.77 billion number of mobile phone users in globally and it is expected to pass the five billion by 2019. [1] The main attribute of this significant increasing trend is due to increasing popularity of smartphones. In 2012, about a quarter of all mobile users were smartphone users and this will be doubled by 2018 which mean there are be more than 2.6 million smartphone users. Of these smartphone users more than quarter are using Samsung and Apple smartphone.
Until 2016, there are 2.2 million and 2 million of apps in google app store and apple store respectively. Such explosive growth of apps gives potential benefit to developer and also companies. There are about $88.3 billion revenue for mobile application market.
Prominent exponents of the IT industry estimated that the IoT paradigm will generate $1.7 trillion in value added to the global economy in 2019. By 2020 the Internet of Things device will more than double the size of the smartphone, PC, tablet, connected car, and the wearable market combined.
Technologies and services belonging to the Internet of Things have generated global revenues in $4.8 trillion in 2012 and will reach $8.9 trillion by 2020, growing at a compound annual rate (CAGR) of 7.9%.
From this impressive market growth, malicious attacks also have been increased dramatically. According to Kaspersky Security Network(KSN) data report, there has been more than 171,895,830 malicious attacks from online resources among word wide. In second quarter of 2016, they have detected 3,626,458 malicious installation packages which is 1.7 times more than first quarter of 2016. Type of these attacks are broad such as RiskTool, AdWare, Trojan-SMS, Trojan-Dropper, Trojan, Trojan-Ransom,Trojan-Spy,Trojan-Banker,Trojan-Downloader,Backdoor, etc..
http://resources.infosecinstitute.com/internet-things-much-exposed-cyber-threats/#gref
Unfortunately, the rapid diffusion of the Internet of Things paradigm is not accompanied by a rapid improvement of efficient security solutions for those “smart objects”, while the criminal ecosystem is exploring the technology as new attack vectors.
Technological solutions belonging to the Internet of Things are forcefully entering our daily life. Let’s think, for example, of wearable devices or the SmartTV. The greatest problem for the development of the paradigm is the low perception of the cyber threats and the possible impact on privacy.
Cybercrime is aware of the difficulties faced by the IT community to define a shared strategy to mitigate cyber threats, and for this reason, it is plausible that the number of cyber attacks against smart devices will rapidly increase.
As long there is money to be made criminals will continue to take advantage of opportunities to pick our pockets. While the battle with cybercriminals can seem daunting, it’s a fight we can win. We only need to break one link in their chain to stop them dead in their tracks. Some tips to success:
- Deploy patches quickly
- Eliminate unnecessary applications
- Run as a non-privileged user
- Increase employee awareness
- Recognize our weak points
- Reducing the threat surface
Currently, both major app store companies, Google and Apple, takes different position to approach spam app detection. One takes an active and the other with passive approach.
There is strong request of malware detection from global
Background (Previous Study)
The paper “Early Detection of Spam Mobile Apps” was published by dr. Surangs. S with his colleagues at the 2015 International World Wide Web conferences. In this conference, he has been emphasised importance of early detection of malware and also introduced a unique idea of how to detect spam apps. Every market operates with their policies to deleted application from their store and this is done thru continuous human intervention. They want to find reason and pattern from the apps deleted and identified spam apps.
The diagram simply illustrates how they approach the early spam detection using manual labelling.





Data Preparation
New dataset was prepared from previous study [53]. The 94,782 apps of initial seed were curated from the list of apps obtained from more than 10,000 smartphone users. Around 5 months, researcher has been collected metadata from Goole Play Store about application name, application description, and application category for all the apps and discarded non-English description app from the metadata.
Sampling and Labelling Process
One of important process of their research was manual labelling which was the first methodology proposed and this allows to identify the reason behind their removal.
Manual labelling was proceeded around 1.5 month with 3 reviewers at NICTA. Each reviewer labelled by heuristic checkpoint points and majority reason of voting were denoted as following Graph3. They identified 9 key reasons with heuristic checkpoints. These full list checkpoints can be find out from their technical report. (http://qurinet.ucdavis.edu/pubs/conf/www15.pdf)[]
In this report, we only list checkpoints of the reason as spam.
Graph3. Labelled spam data with checkpoint reason.

Checkpoint S1-Does the app description describe the app function clearly and concisely?
100 word bigrams and trigrams were manually conducted from previous studies which describe app functionality. There is high probability of spam apps not having clear description. Therefore, 100 words of bigrams and trigrams were compared with each description and counted frequency of occurrence.
Checkpoint S2-Does the app description contain too much details, incoherent text, or unrelated text?
literary style, known as Stylometry, was used to map checkpoint2. In study, 16 features were listed in table 2.
Table 2. Features associated with Checkpoint 2
|
Feature |
|
|
1 |
Total number of characters in the description |
|
2 |
Total number of words in the description |
|
3 |
Total number of sentences in the description |
|
4 |
Average word length |
|
5 |
Average sentence length |
|
6 |
Percentage of upper case characters |
|
7 |
Percentage of punctuations |
|
8 |
Percentage of numeric characters |
|
9 |
Percentage of common English words |
|
10 |
Percentage of personal pronouns |
|
11 |
Percentage of emotional words |
|
12 |
Percentage of misspelled word |
|
13 |
Percentage of words with alphabet and numeric characters |
|
14 |
Automatic readability index(AR) |
|
15 |
Flesch readability score(FR) |
For the characterization, feature selection of greedy method [ ] was used with max depth 10 of decision tree classification. The performance was optimized by asymmetric F-Measure
 [55]
[55]
They found that Feature number 2, 3, 8, 9, and 10 were most discriminativeand spam apps tend to have less wordy app description compare to non-spam apps. About 30% spam app had less than 100 words description.
Checkpoint S3 – Does the app description contain a noticeable repetition of words or key words?
They used vocabulary richness to deduce spam apps.
Vocabulary Richness(VR) =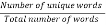
Researcher expected low VR for spam apps according to repetition of keywords. However, result was opposite to expectation. Surprisingly VR close to 1 was likely to be spam apps and none of non-spam app had high VR result. [ ]
This might be due to terse style of app description among spam apps.
Checkpoint S4 – Does the app description contain unrelated keywords or references?
Common spamming technique is adding unrelated keyword to increase search result of app that topic of keyword can vary significantly. New strategy was proposed for these limitations which is counting the mentioning of popular applications name from app’s description.
In previous research name of top-100 apps were used for counting number of mentioning.
Only 20% spam apps have mentioned the popular apps more than once in their description. Whereas, 40 to 60 % of non-spam had mention more than once. They found that many of top-apps have social media interface and fan pages to keep connection with users. Therefore, theses can be one of identifier to discriminate spam of non-spam apps.
Checkpoint S5 – Does the app description contain excessive references to other applications from the same developer?
Number of times a developer’s other app names appear.
Only 10 spam apps were considered as this checkpoint because the description contained links to the application rather than the app names.
Checkpoint S6 – Does the developer have multiple apps with approximately the same description?
For this checkpoint, 3 features were considered:
- The total number of other apps developed by same developer.
- The total number of apps that written in English description to measure description similarity.
- Have description Cosine similarity(s) of over 60%, 70%, 80%, and 90% from the same developer.
Pre-process was required to calculate the cosine similarity: [ ]
Firstly, converting the words in lower case and removing punctuation symbols.
Then calibrate each document with word frequency vector.
Cosine similarity equation:
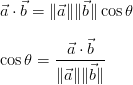
They observed that the most discriminative of the similarity between app descriptions.
Only 10% – 15% of the non-spam had 60% of description similarity between 5 other apps that developed by same developer. On the other hand, more than 27% of the spam apps had 60% of description similarity result. This evidence indicates the tendency of the spam app’s multiple cone with similar app descriptions.
Checkpoint S7 – Does the app identifier (applied) make sense and have some relevance to the functionality of the application or does it appear to be auto generated?
Application identifier(appid) is unique identifier in Google Play Store, name followed by the Java package naming convention. Example, for the facebook , appid is com.facebook.katana.
For 10% of the spam apps the average word length is higher than 10 and it was so only for 2%-3% of the non-spam apps. None of the non-spam apps had more than 20% of non-letter bigram appear in the appid, whereas 5% of spam apps had.
Training and Result
From 1500 of random sampling data 551 apps (36.73%) were suspicious as spam. [ ]
Methods
Automation
We used Checkpoint S1 and S2 for data management due to its comparability and highest number of agreement from reviewers. Due to limitation of accessibility for collect description reason only 100 sample was used for the testing.
We have automated checkpoint S1 and S2 according to following algorithm. Collected data were used log transformation to modify. This can be valuable both for making patterns in the data more interpretable and for helping to meet the assumptions of inferential statistics.
To make a code most time consuming part was description collection which takes more than two weeks to find and store. The raw data directed the description link for appID. However, many of them where not founded due to old version or no more available. So we searched all this info manually from the web and founded description was saved as a file which named as appID. (Diagram.) This allowed us to recall the description more efficiently in automation code.
S1 was automated by identified 100 word-bigrams and word-trigrams that are describing a functionality of applications. Because there is high probability of spam app doesn’t have these words in their description, we have counted number of occurrence in each application.
Full list of these bigrams and trigrams found in Table 1.
Table 1. Bigrams and trigrams using the description of top apps
|
play games |
are available |
is the game |
|
app for android |
you can |
get notified |
|
to find |
learn how |
get your |
|
is used to |
your phone |
to search |
|
way to |
core functionality |
a simple |
|
match your |
is a smartphone |
available for |
|
app for |
to play |
key features |
|
stay in touch |
this app |
is available |
|
that allows |
to enjoy |
take care of |
|
you have to |
you to |
can you beat |
|
buy your |
is effortless |
its easy |
|
to use |
try to |
allows you |
|
keeps you |
action game |
take advantage |
|
tap the |
take a picture |
save your |
|
makes it easy |
follow what |
is the free |
|
is a global |
brings together |
choose from |
|
is a free |
discover more |
play as |
|
on the go |
more information |
learn more |
|
turns on |
is an app |
face the challenges |
|
game from |
in your pocket |
your device |
|
on your phone |
make your life |
with android |
|
it helps |
delivers the |
offers essential |
|
is a tool |
full of features |
for android |
|
lets you |
is a simple |
it gives |
|
support for |
need your help |
enables your |
|
game of |
how to play |
at your fingertips |
|
to discover |
brings you |
to learn |
|
this game |
play with |
it brings |
|
navigation app |
makes mobile |
is a fun |
|
your answer |
drives you |
strategy game |
|
is an easy |
game on |
your way |
|
app which |
on android |
application which |
|
train your |
game which |
helps you |
|
make your |
S2 was second highest number of agreement from three reviewers in previous study. Among 551 identified spam apps, 144 apps were confirmed by S2, 63 from 3 reviewers and 81 from 2 reviewer agreed.
We knew that from pre-research result, total number of words in the description, Percentages of numeric characters, Percentage of non-alphabet characters, and Percentage of common English words will give most distinctive feature. Therefore, we automated total number of words in the description and Percentage of common English words using C++.
Algorithm 1. Counting the total number of bi/tri-grams in the description
From literature [], they used 16 features of to find the information from checkpointS2. This characterization was done with wrapper method using decision tree classifier and they have found 30% of spam apps were have less than 100 words in their description and only 15% of most popular apps have less than 100 words. We extracted simple but key point from their result which was number of words in description and the percentage of common English words. This was developed in C++ as followed.
Algorithm 2. Counting the total number of words in the description
int count_Words(std::string input_text){
int number_of_words =1;
for(int i =0; i < input_text.length();i++){
if(input_text[i] == ‘ ‘)
number_of_words++;
return number_of_words;
}
}
Percentage of common English words has not done properly due to difficulty of standard selection. However, here is code that we will develop in future study.
Algorithm 3. Calculate the Percentage of common English words(CEW) in the description
Int count_CEW(std::string input_text){
Int number_of_words=1;
For(int i<0; i<input_text.length(); i++){
while(!CEW.eof(){
if(strcmp(input_text[i],CEW){
number_of_words++;
}
else{
getline(readFile, CEW);
}
}
return number_of_words;
}
Int percentage(int c_words, int words){
return (c_words/words)*100
}
Normalizaton
We had variables between [ min, max] for S1 and S2. Because of high skewness of database, normalization was strongly required. Database normalization is the process of organizing data into tables in such a way that the results of using the database are always unambiguous and as intended. Such normalization is intrinsic to relational database theory.

Using Excel, we had normalized data as following diagram.
Thru normalization, we could have result of transformed data between 0 and 1. The range of 0 and 1 was important for later process in LVQ.
Diagram. Excel spread sheet of automated data(left) and normalized data (right)

After transformation we wanted to test data to show how LVQ algorithm works with modified attributes. Therefore, we sampled only 100 data from modified data set. Even the result was not significant, it was important to test. Because, after this step, we can add more attributes in future study and possible to adjust the calibration. We have randomly sampled 50 entities from each top rank 100 and from pre-identified spam data. Top 100 ranked apps was assumed and high likely identify as non-spam apps.
Diagram.
Initial Results
We used the statistical package python to perform Learning Vector Quantification.
LVQ is prototype-bases supervised classification algorithm which belongs to the field of Artificial Neural Networks. It can have implemented for multi-class classification problem and algorithm can modify during training process.
The information processing objective of the algorithm is to prepare a set of codebook (or prototype) vectors in the domain of the observed input data samples and to use these vectors to classify unseen examples.
An initially random pool of vectors was prepared which are then exposed to training samples. A winner-take-all strategy was employed where one or more of the most similar vectors to a given input pattern are selected and adjusted to be closer to the input vector, and in some cases, further away from the winner for runners up. The repetition of this process results in the distribution of codebook vectors in the input space which approximate the underlying distribution of samples from the test dataset
Our experiments are done using only the for the manufactured products due to data size. We performed 10-fold cross validation on the data. It gives us the average value of 56%, which was quite high compare to previous study considering that only two attributes are used to distribute spam, non-spam.
LVQ program was done by 3 steps; [ ]
- Euclidean Distance
- Best Matching Unit
- Training Codebook Vectors
1. Euclidean Distance.
Distance between two rows in a dataset was required which generate multi-dimensions for the dataset.
The formula for calculating the distance between dataset
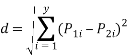
Where the difference between two datasets was taken, and squared, and summed for p variables
def euclidean_distance(row1, row2):
distance = 0.0
for i in range(len(row1)-1):
distance += (row1[i] – row2[i])**2
return sqrt(distance)
2. Best Matching Unit
Once all the data was converted using Euclidean Distance, these new piece of data should sorted by their distance.
def get_best_matching_unit(codebooks, test_row):
distances = list()
for codebook in codebooks:
dist = euclidean_distance(codebook, test_row)
distances.append((codebook, dist))
distances.sort(key=lambda tup: tup[1])
return distances [0][0]
3. Training Codebook Vectors
Patterns were constructed from random feature in the training dataset
def random_codebook(train):
n_records = len(train)
n_features = len(train [0])
codebook = [train[randrange(n_records)][i] for i in range(n_features)]
return codebook
Future work
During writing process, I found that data collection from Google Play Store can be automated using Java client. This will induce number of dataset and possible to improve accuracy with high time saving. Because number of attributes and number of random sampling, result of the research is appropriate to call as significant result. However, basic framework was developed to improve accuracy.
Acknowledgement
In the last summer, I did some research reading work under the supervision of Associate Professor Julian Jang-Jaccard. I’ve got really great support from Julian and INMS. Thanks to the financial support I received from INMS that I can fully focused on my academic research and benefited a great deal from this amazing opportunity.
The following is a general report of my summer research:
In the beginning of summer, I studied the paper ‘A Detailed Analysis of the KDD CUP 99 Data Set’ by M. Trvallaee et. al. This gave basic idea of how to handle machine learning techniques.
Approach of KNN and LVQ
Main project was followed from a paper ‘Why My App Got Deleted Detection of Spam Mobile Apps’ by Suranga Senevirane et. al.
I have tried my best to keep report simple yet technically correct. I hope I succeed in my attempt.
Reference
Appendix
Modified Data
|
Number of Words in thousands |
bigram/tr-gram |
Identified as spam(b)/not(g) |
|
0.084 |
0 |
b |
|
0.18 |
0 |
b |
|
0.121 |
0 |
b |
|
0.009 |
1 |
b |
|
0.241 |
0 |
b |
|
0.452 |
0 |
b |
|
0.105 |
1 |
b |
|
0.198 |
0 |
b |
|
0.692 |
1 |
b |
|
0.258 |
1 |
b |
|
0.256 |
1 |
b |
|
0.225 |
0 |
b |
|
0.052 |
0 |
b |
|
0.052 |
0 |
b |
|
0.021 |
0 |
b |
|
0.188 |
1 |
b |
|
0.188 |
1 |
b |
|
0.092 |
1 |
b |
|
0.098 |
0 |
b |
|
0.188 |
1 |
b |
|
0.161 |
1 |
b |
|
0.107 |
0 |
b |
|
0.375 |
0 |
b |
|
0.195 |
0 |
b |
|
0.112 |
0 |
b |
|
0.11 |
1 |
g |
|
0.149 |
1 |
g |
|
0.368 |
1 |
g |
|
0.22 |
1 |
g |
|
0.121 |
1 |
g |
|
0.163 |
1 |
g |
|
0.072 |
1 |
g |
|
0.098 |
1 |
g |
|
0.312 |
1 |
g |
|
0.282 |
1 |
g |
|
0.229 |
1 |
g |
|
0.256 |
1 |
g |
|
0.298 |
0 |
g |
|
0.092 |
0 |
g |
|
0.189 |
0 |
g |
|
0.134 |
1 |
g |
|
0.157 |
1 |
g |
|
0.253 |
1 |
g |
|
0.12 |
1 |
g |
|
0.34 |
1 |
g |
|
0.57 |
1 |
g |
|
0.34 |
1 |
g |
|
0.346 |
1 |
g |
|
0.126 |
1 |
g |
|
0.241 |
1 |
g |
|
0.162 |
1 |
g |
|
0.084 |
0 |
g |
|
0.159 |
0 |
g |
|
0.253 |
1 |
g |
|
0.231 |
1 |
g |
|
0.251 |
1 |
g |
|
0.362 |
1 |
g |
|
0.129 |
1 |
g |
|
0.186 |
1 |
g |
|
0.102 |
1 |
g |
|
0.267 |
1 |
g |
|
0.086 |
1 |
g |
|
0.043 |
1 |
g |
|
0.17 |
0 |
g |
|
0.12 |
1 |
g |
|
0.294 |
1 |
g |
|
0.341 |
0 |
g |
|
0.261 |
0 |
g |
|
0.12 |
1 |
g |
|
0.289 |
1 |
g |
|
0.256 |
1 |
g |
|
0.14 |
1 |
g |
|
0.098 |
1 |
g |
|
0.134 |
0 |
g |
|
0.266 |
1 |
g |
|
0.254 |
0 |
g |
|
0.237 |
0 |
g |
|
0.431 |
1 |
g |
|
0.102 |
1 |
g |
|
0.056 |
1 |
g |
|
0.187 |
1 |
g |
|
0.121 |
1 |
g |
|
0.227 |
1 |
g |
|
0.105 |
1 |
g |
|
0.076 |
0 |
g |
|
0.12 |
0 |
g |
|
0.065 |
1 |
g |
|
0.043 |
0 |
g |
|
0.109 |
1 |
g |
|
0.254 |
1 |
g |
|
0.176 |
1 |
g |
|
0.472 |
1 |
g |
|
0.231 |
1 |
g |
|
0.178 |
1 |
g |
|
0.143 |
0 |
g |
|
0.264 |
1 |
g |
|
0.156 |
1 |
g |
|
0.176 |
1 |
g |
|
0.253 |
1 |
g |
|
0.176 |
0 |
g |
Order Now