IVR Cloud Migration Project
The primary objective of the IVR Cloud Migration Project is to Lift and Shift their working Applications into the AWS Cloud Environment. The Lift and Shift of the IVR Applications are recommended to have automation the least amount of human interaction to build and deploy onto AWS Cloud. This document will give a step-by-step process to carry out the task of automating the creation and maintenance of the applications.
The IVR Applications require the following resources to replicate and automate the on-premise environment onto AWS Cloud.
In the Automation Process, the requirement is to have minimal human interaction and have an automation pipeline from creating a build for the application to creating, deploying and configuring until a running application instance is setup.
The tools that are required are as follows:
- AWS EC2 Instances
- WebSphere Liberty Profile
- Jenkins Pipeline
- CyberArk Authentication
- Ansible Tower
- AWS CloudFormation
- AWS Elastic Load Balancers
- AWS S3 Bucket
Elastic Compute Cloud (EC2) is a virtual computing environment which provides users the platform to create applications and allowing them to scale their applications by providing Infrastructure as a Service.
Key Concepts associated with an EC2 are –
- Virtual computing environments are known as instances.
- Preconfigured templates for your instances, known as Amazon Machine Images (AMIs), that package the bits you need for your server (including the operating system and additional software).
- Various configurations of CPU, memory, storage, and networking capacity for your instances, known as instance types.
- Secure login information for your instances using key pairs (AWS stores the public key, and you store the private key in a secure place).
- Storage volumes for temporary data that’s deleted when you stop or terminate your instance, known as instance store volumes.
- Persistent storage volumes for your data using Amazon Elastic Block Store (Amazon EBS), known as Amazon EBS volumes.
- Multiple physical locations for your resources, such as instances and Amazon EBS volumes, known as regions and Availability Zones.
- A firewall that enables you to specify the protocols, ports, and source IP ranges that can reach your instances using security groups.
- Static IPv4 addresses for dynamic cloud computing, known as Elastic IP addresses.
- Metadata, known as tags, that you can create and assign to your Amazon EC2 resources.
- Virtual networks you can create that are logically isolated from the rest of the AWS Cloud, and that you can optionally connect to your own network, known as Virtual Private Clouds (VPCs).
IBM WebSphere Application Server V8.5 Liberty Profile is a composable, dynamic application server environment that supports development and testing of web applications.
The Liberty profile is a simplified, lightweight development and application runtime environment that has the following characteristics:
- Simple to configure. Configuration is read from an XML file with text-editor friendly syntax.
- Dynamic and flexible. The run time loads only what your application needs and recomposes the run time in response to configuration changes.
- Fast. The server starts in under 5 seconds with a basic web application.
- Extensible. The Liberty profile provides support for user and product extensions, which can use System Programming Interfaces (SPIs) to extend the run time.
Jenkins is a self-contained, open source automation server which can be used to automate all sorts of tasks such as building, testing, and deploying software. Jenkins can be installed through native system packages, Docker, or even run standalone by any machine with the Java Runtime Environment installed.
Jenkins Pipeline is a suite of plugins which supports implementing and integrating continuous delivery pipelines into Jenkins. Pipeline provides an extensible set of tools for modeling simple-to-complex delivery pipelines “as code”.
A “Jenkinsfile” which is a text file that contains the definition of a Jenkins Pipeline is checked into source control. This is the foundation of “Pipeline-As-Code”; treating the continuous delivery pipeline a part of the application to be version and reviewed like any other code.
REQUIREMENTS –
The Requirements for Jenkins Server includes the following:
- The size requirement for a Jenkins instance is that there is no “one size fits all” answer – the exact specifications of the hardware that you will need will depend heavily on your organization’s needs.
- Your Jenkins master runs on Java and requires to have the OpenJDK installed on the Instance with the JAVA_HOME path Set.
- Jenkins runs on a local webserver like Tomcat and requires it to be configured.
- RAM allotted for it can range from 200 MB for a small installation to 70+ GB for a single and massive Jenkins master. However, you should be able to estimate the RAM required based on your project build needs.
- Each build node connection will take 2-3 threads, which equals about 2 MB or more of memory. You will also need to factor in CPU overhead for Jenkins if there are a lot of users who will be accessing the Jenkins user interface.
- The more automated the environment configuration is, the easier it is to replicate a configuration onto a new agent machine. Tools for configuration management or a pre-baked image can be excellent solutions to this end. Containers and virtualization are also popular tools for creating generic agent environments.
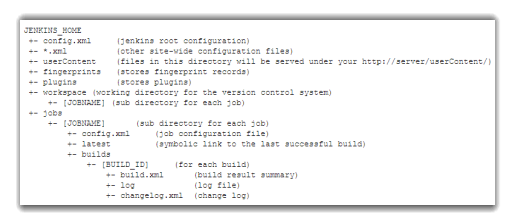
Jenkins File Structure is a model to automate the non-human part of the whole software development process, with now common things like continuous integration, but by further empowering teams to implement the technical part of a Continuous Delivery.
|
Directory |
Description |
|
. jenkins |
The default Jenkins home directory. |
|
Fingerprints |
This directory is used by Jenkins to keep track of artifact fingerprints. We look at how to track artifacts later in the book. |
|
jobs |
This directory contains configuration details about the build jobs that Jenkins manages, as well as the artifacts and data resulting from these builds. |
|
plugins |
This directory contains any plugins that you have installed. Plugins allow you to extend Jenkins by adding extra feature. Note – Except the Jenkins core plugins (subversion, cvs, ssh-slaves, maven, and scid-ad), no plugins are stored with Jenkins executable, or expanded web application directory. |
|
updates |
This is an internal directory used by Jenkins to store information about available plugin updates. |
|
userContent |
You can use this directory to place your own custom content onto your Jenkins server. You can access files in this directory at http://myserver/userContent (stand-alone). |
|
users |
If you are using the native Jenkins user database, user accounts will be stored in this directory. |
|
war |
This directory contains the expanded web application. When you start Jenkins as a stand-alone application, it will extract the web application into this directory. |
JENKINS SETUP –
Jenkins Setup is carried out on a managing server which has access to all your remote servers or nodes. The Process can be demonstrated with a few simple steps.
Jenkins has native integrations with different Operating Systems. These are the Operating Systems that support Jenkins are:
JENKINS CONFIGURATION –
The Configuration file for Jenkins is used to make certain changes to the default configuration. The Priority configuration changes are searched by Jenkins in the following order:
- Jenkins will be launched as a daemon on startup. See /etc/init.d/jenkins for more details.
- The ‘jenkins’ user is created to run this service. If you change this to a different user via the config file, you must change the owner of /var/log/jenkins, /var/lib/jenkins, and /var/cache/jenkins.
- Log file will be placed in /var/log/jenkins/jenkins.log. Check this file if you are troubleshooting Jenkins.
- /etc/sysconfig/jenkins will capture configuration parameters for the launch.
- By default, Jenkins listen on port 8080. Access this port with your browser to start configuration. Note that the built-in firewall may have to be opened to access this port from other computers.
- A Jenkins RPM repository is added in /etc/yum.repos.d/jenkins.repo
The requirement for creating a pipeline is to have a repository with the Jenkins file which holds the declaration of the pipeline.
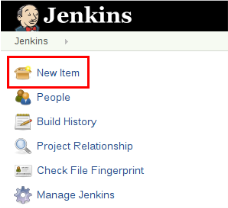
STEP 1:
Select New Item from the Jenkins Dashboard.
STEP 2:

Enter a Name for the Pipeline and Select Pipeline from the list of options. Click OK.
STEP 3:
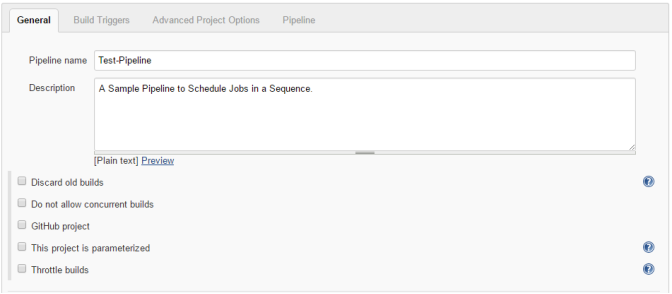
Toggle Tabs to Customize the Pipeline to Click Apply.
STEP 4:
To Build the Job, Click Build Now on the Dashboard to run the Pipeline.

Ansible Tower is the Automation tool used in this project and is a simple tool to manage multiple nodes. Ansible is recommended to automate the deployment and configuration management of the System and its Applications.
Ansible Automation can be setup on any machine as it does not require a daemon or database. It will begin with the assigned user to SSH into a host file. This allows the user to run the Ansible script to execute the roles which runs various tasks defined.
NOTE: In scope of the IVR applications the ansible script executes multiple roles for the creation of EC2 Instances and the installation of WebSphere Applications. Each of these roles have their very own YAML script to create and populate the instance.
REQUIREMENTS –
The Requirements for Ansible Server includes the following:
Ansible Tower Setup requires to be on a Linux Instance (CentOS or RHEL),
Linux setup for some basic services including: Git, Python, OpenSSL.
Some Additional Requirement:
- Jinja2: A modern, fast and easy to use stand-alone template engine for Python.
- PyYAML: A YAML parser and emitter for the Python programming language.
- Paramiko: A native Python SSHv2 channel library.
- Httplib2: A comprehensive HTTP client library.
- SSHPass: A non-interactive SSH password authentication.
Ansible Playbook is a model of configuration or a process which contains number of plays. Each play is used to map a group of hosts to some well-defined roles which can be represented by ansible call tasks.
- Master Playbook – The Master Playbook file contains the information of the rest of the Playbook.
The Master Playbook for the project has been given as Site.yml.
This YAML script is used to define the roles to execute.
NOTE: The roles in the Master Playbook are invoked to perform their respective tasks.
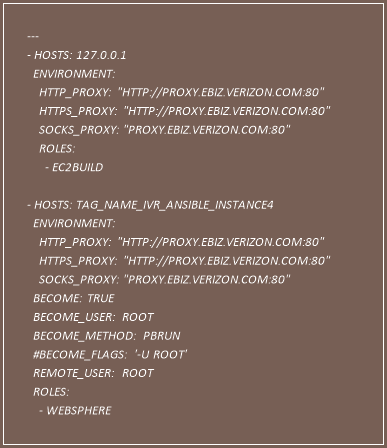
Path = ‘/ivr/aws_env/playbooks/ivr’
SITE.YML
Inventory – Ansible contains information about the hosts and groups of hosts to be managed in the hosts file. This is also called an inventory file.
Path = ‘/ivr/aws_env/playbooks/ivr/inventory’
Group Variables and Host Variables – Similar to the hosts inventory file, you can also include hosts and groups of hosts configuration variables in a separate configuration folder like group_vars and hosts_vars.
These can include configuration parameters, whether on the application or operating system level, which may not be valid for all groups or hosts.
This is where having multiple files can be useful: inside group_vars or hosts_vars, you can create a group or host in more than one way, allowing you to define specific configuration parameters.
Roles – Roles in Ansible build on the idea of include files and combine them to form clean, reusable abstractions – they allow you to focus more on the big picture and only define the details when needed. To correctly use roles with Ansible, you need to create a roles directory in your working Ansible directory, and then any necessary sub-directories.
The Following displays the Playbook Structure for Ansible.

Ansible Setup is carried out on a managing server which has access to all your remote servers or nodes. The Process can be demonstrated with a few simple steps.
Step I.
Login as the Root User on the Instance where Ansible needs to be installed.
Use the sudo apt-get install ansible -y command to install the package onto an Ubuntu/Debian System.
Use the sudo yum install ansible -y command to install the package onto a CentOS/RHEL/Fedora System.
Step II.
The Ansible system can connect to any remote server using SSH by authenticating the request.
NOTE: Ansible can use ssh-keygen to create a RSA encrypted key and can copy it to the remote server to connect using SSH without authentication.
Step III.
Create an Inventory file which is used to work against multiple systems across the infrastructure at the same time. This is executed by taking portions of the systems linked in the Inventory file.
The Default path for the Inventory file is ‘etc/ansible/hosts’.
NOTE – This path can be changed by using -i <path> which is a recommended option depending on the project requirement.
There can be more than one inventory files which can be executed at the same time. The inventory file holds the group names which defines the group of servers that are maintained together.
The inventory file needs to be populated with the host IP Addresses that are to be accessed.
The inventory file is as follows:
Path = ‘/ivr/aws_env/playbooks/ivr/inventory’

hosts
The ‘IVR’ in the brackets indicates group names. Group names are used to classify systems and determining which systems you are going to control at what times and for what reason.
The group name can be used to interact with all the hosts alongside different modules (‘-m’) defined in ansible.
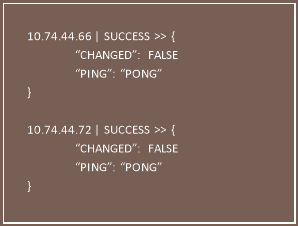
Example: ansible -m ping IVR
ANSIBLE CONFIGURATION –
The Configuration file for Ansible is used to make certain changes to the default configuration.

The Priority configuration changes are searched by ansible in the following order:
Path= ‘/ivr/aws_env/playbooks/ivr/etc/ansible.cfg’ is the path setup for ansible configuration changes.
AWS CloudFormation is a service that helps you model and set up your Amazon Web Services resources so that you can spend less time managing those resources and more time focusing on your applications that run-in AWS.
You create a template that describes all the AWS resources that you want (like Amazon EC2 instances or Amazon RDS DB instances), and AWS CloudFormation takes care of provisioning and configuring those resources for you.
You don’t need to individually create and configure AWS resources and figure out what’s dependent on what; AWS CloudFormation handles all of that.
CloudFormation templates are created for the service or application architectures you want and have AWS CloudFormation use those templates for quick and reliable provisioning of the services or applications (called “stacks”). You can also easily update or replicate the stacks as needed.
Example Template –
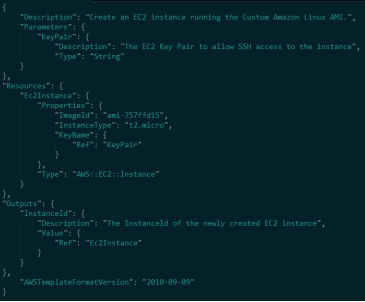
STEPS TO LAUNCH A CLOUD FORMATION STACK –
- Sign in to AWS Management Console and open the Cloud Formation console at http://console.aws.amazon.com/cloudformation/
-
From the navigation bar select the region for the instance – -

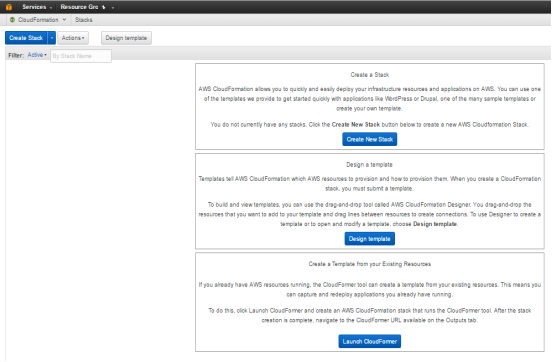
Click on the Create a New Stack. -

Choose an Option from a Sample Template, Template to S3 and S3 Template URL –
- Using a template to build an EC2 Instance –
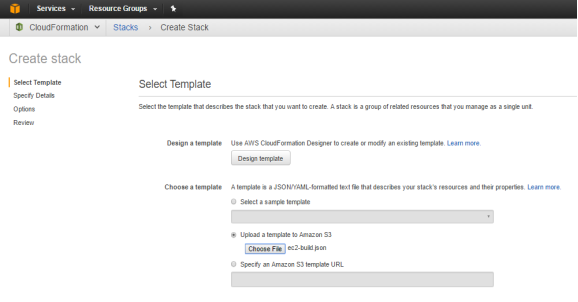

- Enter a Stack Name and Provide the Key Pair to SSH into the Instance.
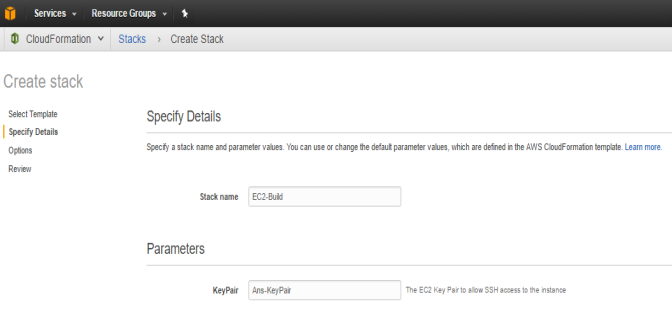
 a
a
 A
A
- Add Tags to the Instance, this also help organize your instance to group with application specific, team specific instances.
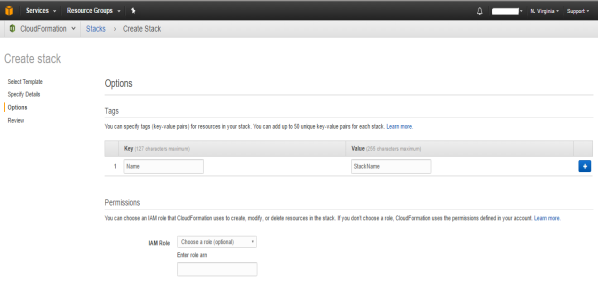


- Review and Create Stack.
- CloudFormation Stack starts building the stack using the template.
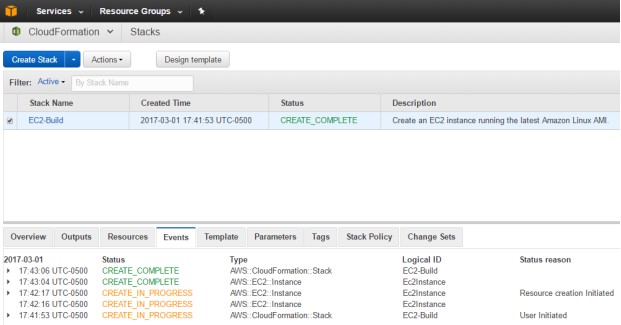
In Scope of this Project, IVR Application Instances are build using a Cloud Formation Template and will be triggered using Ansible Role.
Simple Storage Service (S3)
Elastic Load Balancer (ELB)
A load balancer serves as a single point of contact for clients, which increases the availability of your application. You can add and remove instances from your load balancer as your needs change, without disrupting the overall flow of requests to your application. Elastic Load Balancing scales your load balancer as traffic to your application changes over time, and can scale to the clear majority of workloads automatically.
You can configure health checks, which are used to monitor the health of the registered instances so that the load balancer can send requests only to the healthy instances. You can also offload the work of encryption and decryption to your load balancer so that your instances can focus on their main work.
 Setting Up an Elastic Load Balancer
Step 1: Select a Load Balancer Type
Elastic Load Balancing supports two types of load balancers:
- Application Load Balancers and
- Classic Load Balancers.
To create an Elastic Load Balancer, Open the Amazon EC2 console and choose Load Balancers on the navigation pane.
Step 2: Configure Your Load Balancer and Listener
On the Configure Load Balancer page, complete the following procedure.
To configure your load balancer and listener
1. For Name, type a name for your load balancer.
The name of your Application Load Balancer must be unique within your set of Application Load Balancers for the region, can have a maximum of 32 characters, can contain only alphanumeric characters and hyphens, and must not begin or end with a hyphen.
2. For Scheme, keep the default value, internet-facing.
3. For IP address type, select ipv4 if your instances support IPv4 addresses or dual stack if they support IPv4 and IPv6 addresses.
4. For Listeners, keep the default, which is a listener that accepts HTTP traffic on port 80.
5. For Availability Zones, select the VPC that you used for your EC2 instances. For each of the two Availability Zones that contain your EC2 instances, select the Availability Zone and then select the public subnet for that Availability Zone.
6. Choose Next: Configure Security Settings.
Step 3: Configure a Security Group for Your Load Balancer
The security group for your load balancer must allow it to communicate with registered targets on both the listener port and the health check port. The console can create security groups for your load balancer on your behalf, with rules that specify the correct protocols and ports.
Note – If you prefer, you can create and select your own security group instead. For more information, see Recommended Rules in the Application Load Balancer Guide.
On the Configure Security Groups page, complete the following procedure to have Elastic Load Balancing create a security group for your load balancer on your behalf.
Step 4: Configure Your Target Group
To configure a security group for your load balancer
1. Choose Create a new security group.
2. Type a name and description for the security group, or keep the default name and description. This
new security group contains a rule that allows traffic to the load balancer listener port that you selected
on the Configure Load Balancer page.
3. Choose Next: Configure Routing.
Step 4: Configure Your Target Group
Create a target group, which is used in request routing. The default rule for your listener routes requests to the to registered targets in this target group. The load balancer checks the health of targets in this target
group using the health check settings defined for the target group. On the Configure Routing page,
complete the following procedure.
To configure your target group
1. For Target group, keep the default, New target group.
2. For Name, type a name for the new target group.
3. Keep Protocol as HTTP and Port as 80.
4. For Health checks, keep the default protocol and ping path.
5. Choose Next: Register Targets.
Step 5: Register Targets with Your Target Group
On the Register Targets page, complete the following procedure.
To register targets with the target group
1. For Instances, select one or more instances.
2. Keep the default port, 80, and choose Add to registered.
3. If you need to remove an instance that you selected, for Registered instances, select the instance
and then choose Remove.
4. When you have finished selecting instances, choose Next: Review.
Step 6: Create and Test Your Load Balancer
Before creating the load balancer, review the settings that you selected. After creating the load balancer, verify that it’s sending traffic to your EC2 instances.
To create and test your load balancer
1. On the Review page, choose Create.
2. After you are notified that your load balancer was created successfully, choose Close.
3. On the navigation pane, under LOAD BALANCING, choose Target Groups.
4. Select the newly created target group.
5. On the Targets tab, verify that your instances are ready. If the status of an instance is initial, it’s probably because the instance is still in the process of being registered, or it has not passed the
Auto Scaling
OVERVIEW
There are 2 Parts of the Automation Process which is used –
- To Create a Custom AMI for all IVR Applications &
- To Create Instances for Each Application using the Custom AMI.
STEPS TO CREATE THE CUSTOM AMI –
- The process of automating this environment starts from creating a Jenkins Pipeline for code deploy to the application that needs to be build.
- The Pipeline also needs integration of CyberArk for the Authentication and registering the service account required for the automation.
- The following process is triggered as part of the Ansible playbook where it performs multiple roles to complete automation of the Application.
- The Ansible role first calls for a CloudFormation Template.
- A CloudFormation Template is used to Build a Stack required (EC2 Instance). This template is given the AMI ID of the Verizon standard.
- The CloudFormation Template after the creation of the Instance triggers a WebSphere Role from Ansible that installs the OpenJDK, WebSphere Liberty Profile, creating a WLP User and Add the Necessary Net groups for the application.
- An AMI of the Instance at this point is created.
STEPS TO CREATE THE APPLICATION INSTANCES –
- The process of automating this environment starts from creating a Jenkins Pipeline for code deploy to the application that needs to be build.
- The Pipeline also needs integration of CyberArk for the Authentication and registering the service account required for the automation.
- The following process is triggered as part of the Ansible playbook where it performs multiple roles to complete automation of the Application.
- The Ansible role first calls for a CloudFormation Template.
- A CloudFormation Template is used to Build a Stack required (EC2 Instance). This template is given the Custom AMI created for IVR.
- After the creation of the Instance an S3 Role is triggered from Ansible.
- The S3 Role Performs the Ansible Role based on the Application Instance.
NOTE: An S3 Bucket with folder structure for each application is maintained to keep the updated code and certificates along with other required installation files.
- IVR Touch Point – S3 role fetches the EAR files, configuration files and the certificates in the IVR-TP folder of the S3 bucket and install them on the Instance that is created by the Cloud Formation Role.
- IVR Middleware – S3 role fetches the EAR files, configuration files and the certificates in the IVR-MW folder of the S3 bucket and install them on the Instance that is created by the Cloud Formation Role.
- IVR Activations – S3 role fetches the EAR files, configuration files and the certificates in the IVR-Activations of the S3 bucket and install them on the Instance that is created by the Cloud Formation Role.
- IVR CTI – S3 role fetches the IBM eXtreme Scale Grid Installation followed by Siteminder SSO installation. After the application requirements are fulfilled, the EAR files, configuration files and the certificates in the IVR-CTI folder of the S3 bucket are deployed on the Instance.
- IVR Work Hub – S3 role fetches the IBM eXtreme Scale Grid Installation followed by Siteminder SSO installation. After the application requirements are fulfilled, the EAR files, configuration files and the certificates in the IVR-Work Hub folder of the S3 bucket are deployed on the Instance.
- IVR Speech – S3 role fetches the EAR files, configuration files and the certificates in the IVR-Speech folder of the S3 bucket and install them on the Instance that is created by the Cloud Formation Role.
- The Server is started on these instances to successfully complete the automation of the instances.
Jenkins Pipeline is the starting point of the automation process. The Pipeline is created to deploy the build, integrate CyberArk and call Ansible to trigger the Cloud Formation Template.
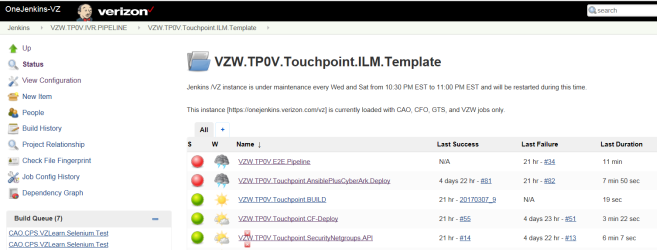
NOTE: A Jenkins Template is created to hold the Pipeline along with all the Jobs that need to be run in the Pipeline.
CREATING THE JENKINS END-TO-END PIPELINE –
Creating this End-to-End Pipeline involves multiple jobs that are queued.
The first job that needs to be executed in the pipeline is to create a build for the Application.
In this End-to-End Pipeline, Jenkins performs these multiple jobs in stages.
The first job that runs on this Jenkins Pipeline is to Build the latest code for the Application.
This is done by calling the Build Job that is added to the Jenkins Template.
BUILD JOB –
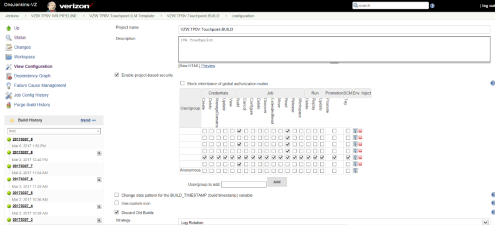
The build job from the template is run in the End to End Pipeline before the automation of the deployment process is started.
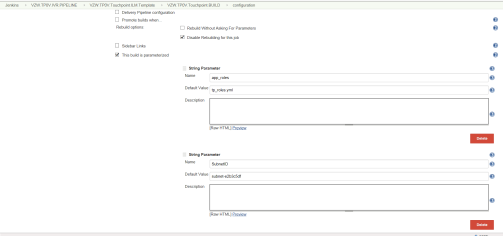
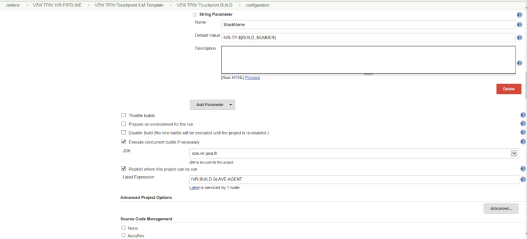
The String Parameters that are passed to the Build Job include Application Roles, Subnet ID, Stack Name and provide the details for the Git repository and its access privileges.
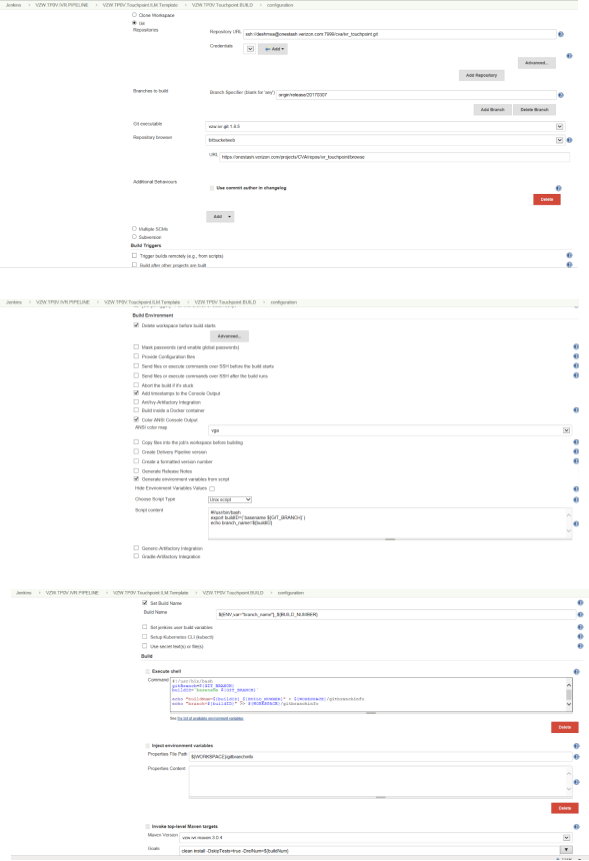

The Custom Parameters like Build number, Git Branch are passed using shell script which is required to run the End to End Pipeline.
BUILD OUTPUT-
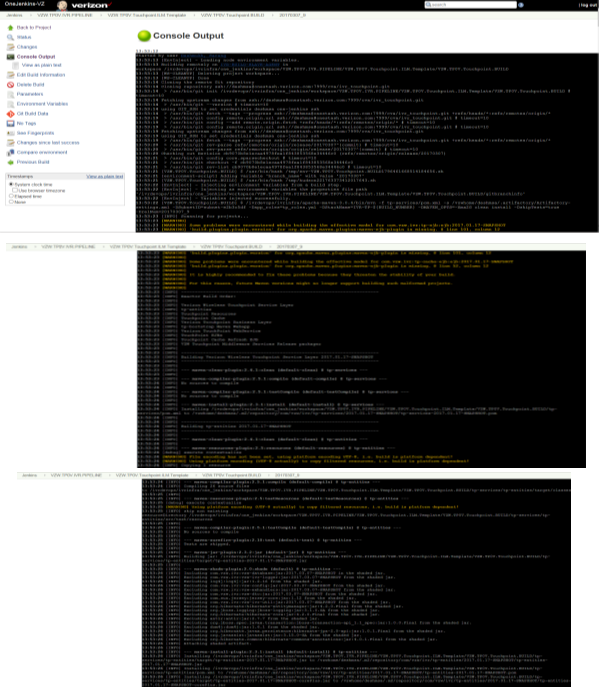 After passing the parameters in the Build Job, the following output is obtained.
After passing the parameters in the Build Job, the following output is obtained.


PIPELINE STAGES:
The Jenkins Pipeline has 3 Stages –
- Provision Base Instance
- Register Security Net Groups
-

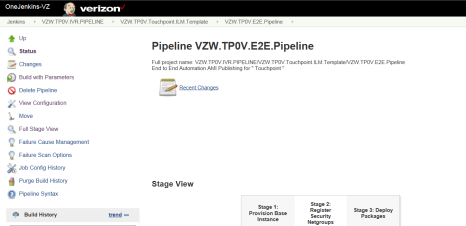
Deploy Packages
The first stage is to provision a base instance which performs the following job –
-
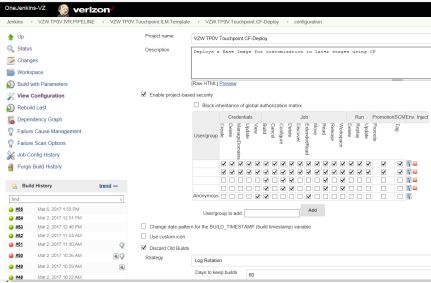
Cloud Formation Deploy
This performs the process of building the stack using the Cloud Formation Template.
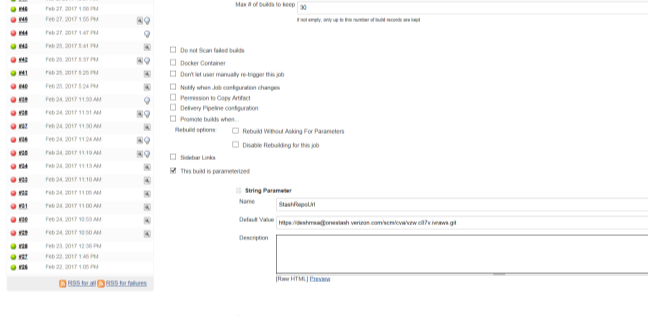
Multiple Parameters need to be passed for a build Job.
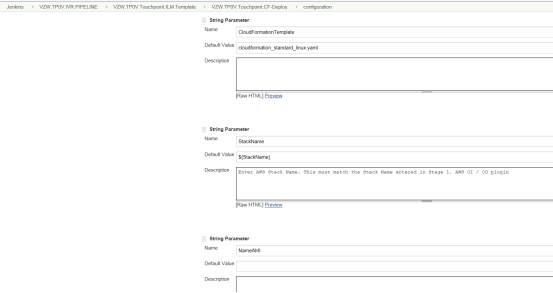
String Parameters are passed for the Stash Repository URL, Cloud Formation Template file, Stack Name, AMI Name.
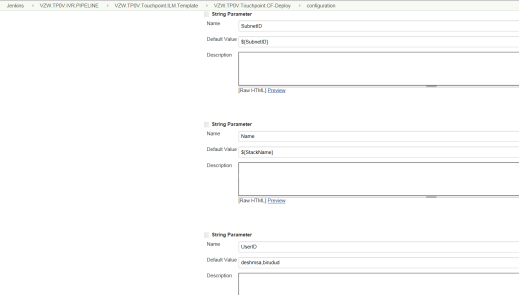
Choice Parameters are passed for Subnet role and Data Classification between Public and Private. Also, the String Parameters Subnet ID, Stack Name, User ID
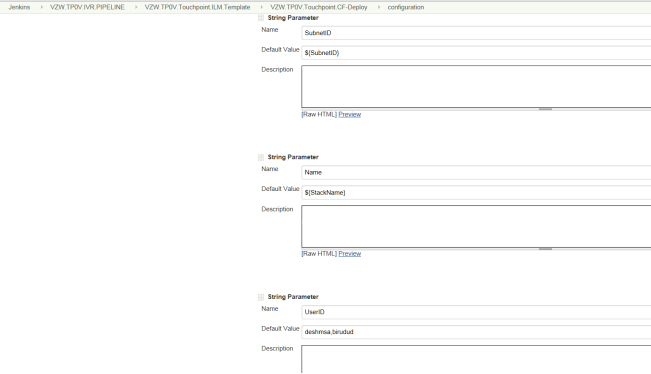
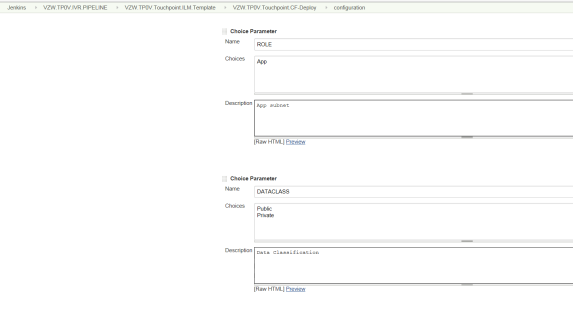
The Cloud Formation CI CD Pipeline needs the following parameters –
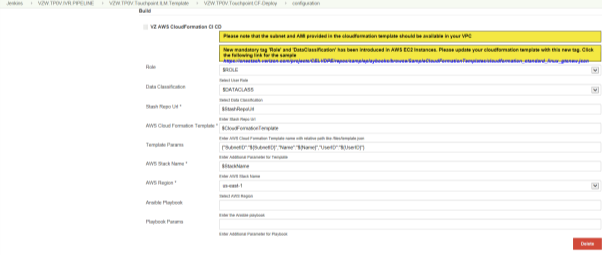
CF-Deploy OUTPUT-
This Jenkins job is used to run the Cloud Formation Template which is executed as an Ansible role.
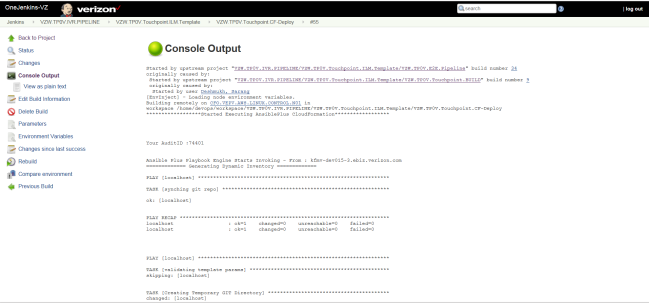
The Output for this Job is as follows –

This stage is to register the net groups that provide access permission to the instance.
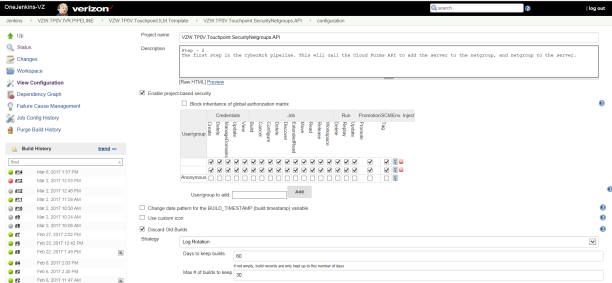
The Jenkins job created is to setup the CyberArk Pipeline and is will need to add the Cloud Forms API to add the server to the net group and then add the net groups to the server.
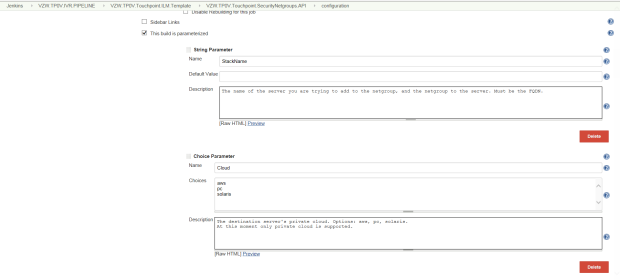
The String Parameter that are passed for this privilege escalation are – Stack Name to add the Net groups & the Choice Parameters that are passed are – Cloud used for the destination server, Environment the destination server is built.

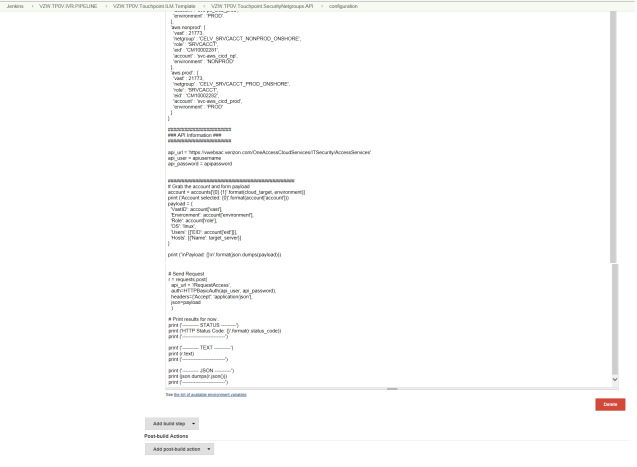
The Python Script in this Build is to send the Authentication request using the service account with all the required parameters which includes
BUILD OUTPUT –

The Output this Jenkins Build shows the Authentication of the Service Account using CyberArk.
This stage is to provide the service account details to authenticate using CyberArk and trigger to deploy using Ansible.

This Jenkins Job is used to provide the service account parameters to authenticate CyberArk to log into the machine created and deploy the necessary application requirements using Ansible.
The String Parameters passed in this Jenkins job are – Stack Name from the Cloud Formation, URL for the Stash Repository and the Target Group ARN for the ELB.
The Choice Parameter passed in this Jenkins job are – Service Account to be used for the CyberArk Authentication and the Application Role to select the Application that needs to be deployed.


BUILD OUTPUT –



Ansible on receiving access performs multiple roles which required to install the resources for the application and to deploy the build files, configuration files and certificates onto the instance.

All the applications in IVR contain application specific tasks which are triggered from a parameterized playbook.
The app_roles.yaml file is the playbook which is triggered to deploy the application.

Each of the applications has its own roles which follow the same process of creating, configuring and deploying the application servers.
The vars in the app_roles.yml file is set to the application to be built.
The roles in the script are the steps required to configure the application environment.
The following flow explains the tasks involved in these roles.
 The first role that is invoked in the playbook is the installation of the AWS CLI on the created stack.
The first role that is invoked in the playbook is the installation of the AWS CLI on the created stack.
The next role that is invoked is the apache role which is used to install required packages along with the HTTPD, Deploy the Web files by extracting the tar, update Kerberos module and finally start and enable the HTTP service.
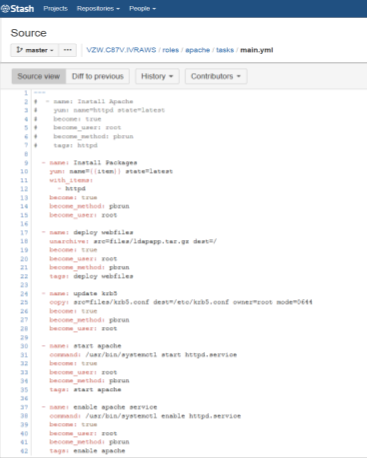
The next role involves the configuration of the Base RHEL Proxy.
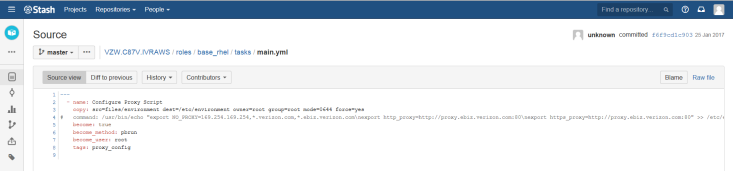
The Configuration of Proxy is invoked to copy the environment to the destination location where the application is deployed.



The S3 role in the playbook is used to invoke the s3 bucket which holds the custom configuration files for all the applications along with their updated binaries and certificates for deployment.
Application Specific S3 Sync –
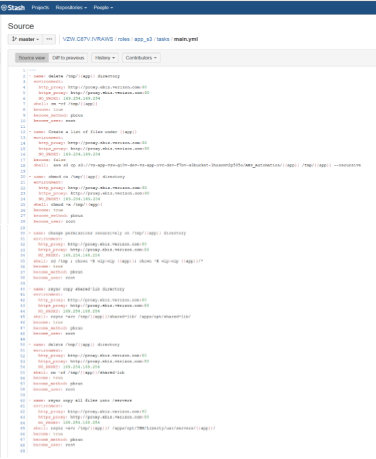 The app_s3 role is used to sync the files from application specific directories on the s3 bucket to the environment setup for the application on the server.
The app_s3 role is used to sync the files from application specific directories on the s3 bucket to the environment setup for the application on the server.

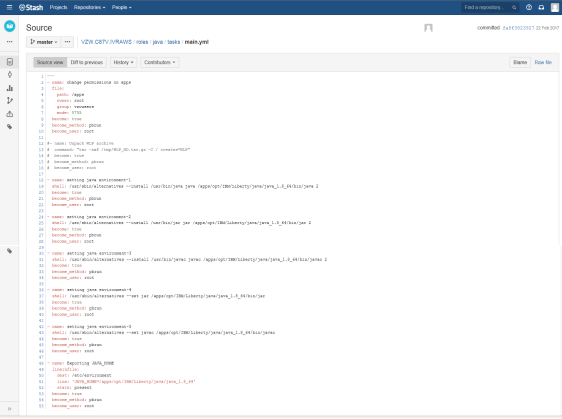 The Java role is used to set the java path for all the environments and JAVA_HOME path.
The Java role is used to set the java path for all the environments and JAVA_HOME path.

 The certs role is invoked to perform the following tasks – create the keystore folder, remove the old keystore folder, create the keystore using keygen with the correct credentials, import the certificate that is created. The source keystore (. p12) file is used to create the certificate into the keystore folder. The certificate is then imported into the cacerts path on the destination server and then update the keystore permissions.
The certs role is invoked to perform the following tasks – create the keystore folder, remove the old keystore folder, create the keystore using keygen with the correct credentials, import the certificate that is created. The source keystore (. p12) file is used to create the certificate into the keystore folder. The certificate is then imported into the cacerts path on the destination server and then update the keystore permissions.

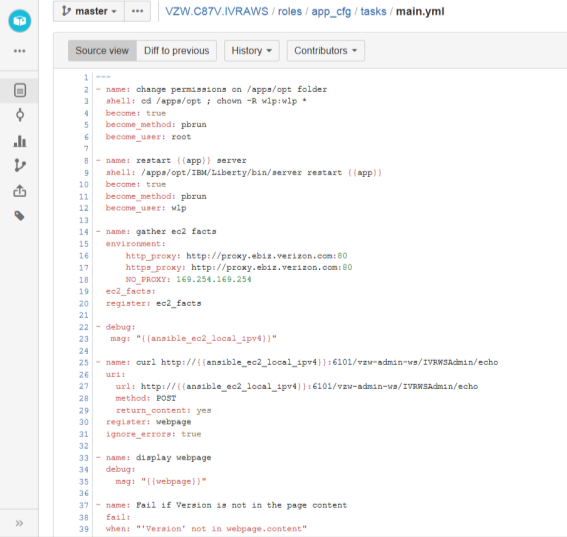
The app_cfg role is invoked to restart the application server, gather the proxy details for the environment, register the webpage and then display the webpage.

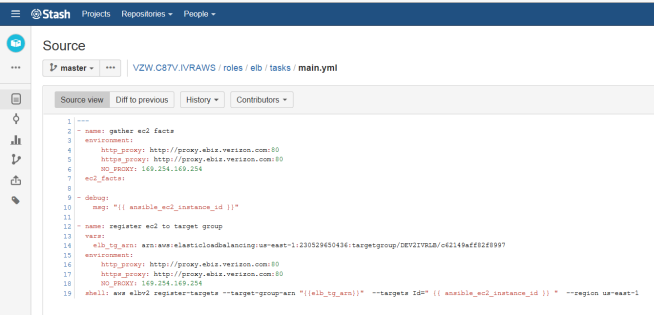
The elb role is the invoked to gather the instance details of the application built followed by registering the instance to the staging Elastic Load Balancer for testing.
This completes the END TO END AUTOMATION of IVR Applications and is common process for all the applications in IVR.
Source Stash Repository of the Automation Process – https://