Social Media in Business and Society




Most organizations tend to look upon social media as a threat, where some even opt to ban the usage from the workplace altogether. The idea behind it being that employees would be given the opportunity to waste time online, chat, and possibly pose as a security threat to the organization. (Turban, 2011)
(Smith, 2010) outlines risk of employees’ social media use at work, these can be both intentional or not and they could lead to legal and reputational risks for organisations. These have been categorised as three main problems:
- Use of social media cannot be fully regulated, monitored or controlled thus organisations are “giving up control”.
- Social media is a worldwide means of communication, once a negative post is online it’s only a matter of time till it goes viral thus reaching competitors, regulators and customers.
- Social media is emotional and employees can express their feelings of happiness and/or frustration.
Furthermore, (Flynn, 2012) identifies the risks of having employees participating in social media by “causing reputational damage, trigger lawsuits, cause humiliation, crush credibility, destroy careers, create electronic business records, and lead to productivity losses”.
(Dreher, 2014) argues that social media is not to be feared, but rather embraced and seen as an opportunity where employees can act as “corporate advocates and brand ambassadors”. If anything, it helps employees keep up to date with latest news related to the industry together with continuous knowledge development. Nonetheless, even though there are many studies that point out the benefits of social media, there is still no clear-cut decision whether it can influence work performance or whether it can fuel the social capital of the employees and help in knowledge transfer (Zhang, 2016).
However, it cannot be denied that every organisation allowing social media at work will always have its fair deal of challenges to overcome. (Eliane Bucher, 2013) speaks about the health issues that can be encountered. Starting off with stating that there is so much information available on social media that professionals may face information overload. Not to mention the mix of work life with private life overlapping with social media.
New technologies should improve worker’s efficiency and reduce stress levels however often the opposite occurs (Eliane Bucher, 2013). Technostress as referred to by (Brod, 1984). To be successful in the social media environment one needs to overcome the below 3 points otherwise technostress is formed:
- Techno-overload – Increase in workload which could be actual or perceived.
- Techno-invasion – Social media enables people to be constantly connected from almost every device. This can lead to the feeling of the “need” to be connected or online causing reduction in family time allowing work issues to invade the private life (Eliane Bucher, 2013).
- Techno-uncertainty – Social media is constantly changing and therefore brings with it uncertainty as regards to what technologies and skills are needed to perform the job and what will they be in the future.
Social media comes with many legal issues tied to it. These range from pre-employment to post employment. Wrong usage of social media will for sure lead to waste of time, inefficiency, reputation issues and negative image for the organisation. Some of the laws are outlined below by (Lieber, 2011):
Employment Laws by tagging co-workers in certain provocative photos or videos,
Defamation and Libel Laws by stating certain comments on co-workers or employers thus effecting their reputation., As stated in (Trott, 2009) a Microsoft Survey found that 41% of employers based their decision of not hiring an applicant based on what they found online in relation to their reputation. This is also known as “Netrep”. This constitutes a legal risk of discrimination in itself if the recruiter is basing decision on the netrep.
Fair Credit Reporting Act by having interviewers “friending” an applicant on Facebook to acquire more information than is required for the job applied.
Health Insurance Portability and Accountability Act by having a medical professional LinkIn with a patient.
Uniform Trade Secrets Act by having employees discussing or commenting on social media about company “internal only” discussions or non-public projects.
Employers can monitor the use of social media at work if the employees are informed in advance. Disciplinary actions can be taken once any abuse is being noticed. Policies should include what is allowed and what is considered as abuse (Trott, 2009).
If the employees post on their personal accounts outside of office hours and such posts are in relation to work having a negative impact in some way to the employer or the organisation then there is still grounds for disciplinary action even though employees try to advocate for “respect for private and family life, home and correspondence” (article 8) or “freedom of expression” (article 10) from the Human Rights Act 1998.
As discussed above, social media has its advantages and disadvantages and seeing that social media is here to stay organisations have little choices but to accept the new reality, address it and learn how to make good use of it. (Lieber, 2011), among others, identifies the following criteria that any organisation willing to harness social media must address:
- The creation and enforcement of solid social media policies within the organisation’s personnel addressing fair use, access during work time and general behaviour on social media (even during personal time).
- Directly using social media for the benefit of the organisation such as for recruitment, marketing and investigating competing organizations.
- Monitoring of key social networks to data mine information regarding your organisation (and potentially others’ as well), possibly using automated algorithms and software for maximum efficiency and accuracy.
From the above-mentioned criteria, the first two deal with “human resource” aspect of social media where organizations lay out guidelines to their employees on how to use them, and they as the organizations can use social media directly for recruitment, marketing etc. However, as the third criteria suggests, to make most use of social networks organizations must make sure that any information/data being released on such platforms, is gathered and used effectively.
It is important that an organization is always aware of what the average user is saying about their brand, effectively getting the general feel or mood while analysing the trends across time. The same principle could be applied to monitor competitors; possibly for example identifying any weak products which the competitors have and having your own similar product take advantage of the situation.
Effective monitoring comes from generating good data. Data mining involves the following steps to make data meaningful for monitoring: (Raghav Bali, 2016)
- Removing unwanted data and noise
- Transformation of the raw data into data that can be used for further processing
- Study the data and come up with patterns that can give further insight to our data
- Represent the data in a way that is useful to companies or to who the data intended for.
There are different data mining techniques which can be used to monitor social media use. Social media is a form of real time communication therefore an effective monitoring tool needs to monitor and provide alerts as things happen. Most text mining tools make use of search engines to go through social media sites and collect information related to the keywords or interests. (Mark My Words article)
Text Analytics (Text/Data Mining)
Text analytics involves a complex and elaborate number of steps to strip down conversations into separate words and analyse the way these words are being used, positive or negative and even derive patterns from collected data.
When we search for a movie and receive some other movie recommendations that technique is using text mining.
Text Mining is made up of Data Mining (Information retrieval, Natural Language Processing & Machine learning) + Text Data (Emails, Tweets, News Articles, Websites, Blogs etc.)
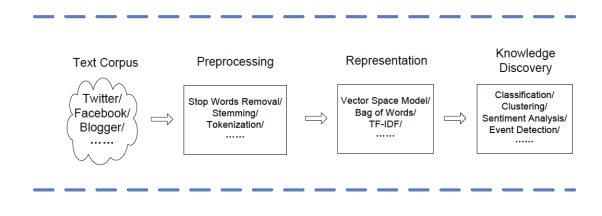
Figure 1: Text Mining (Charu C. Aggarwal, 2012)
As indicated in Figure 1, Stop Word Removal and Stemming eliminate the generic and less meaningful words form a phrase, this helps categorizing different words with same meaning as “see”, “seen” and “being seen”.
Bag of Words (BOW) is having words separated from the sentence and each word having a numerical value which represents its importance.
Limitations
(Charu C. Aggarwal, 2012) outlines several limitations that can be observed and future in-depth research is required:
- The real-time posts on social media are a very important resource as mining data in real time as it is being posted can yield many advantages. This however remains a challenge for when these posts are not conducted from work computers or from outside work.
- Social media is very unstructured and some applications like twitter even limit the amount of characters per post. This brings about problems of text recognition when short length words are used like “gnite” “gr8” etc.
- Social media allows different ways to express opinions or emotions these could be through images, videos and tags making the text analytics much more complex and difficult in its pre-processing stage.
ï‚· Method 1:
Keyword Search (Rappaport, 2010)
Organisations can decide which keywords they want to monitor, these may be chosen based on what is important for that company, it could be their products or emotional states. Social media is a very unstructured place containing noise and unwanted data for our data mining process. This form of search is good to capture keywords and try and form a meaning of these words and the frequency used however it’s very hard to come up with what is the user’s intent. For that reason, we then consider a more complex search method called Sentiment Analysis.
ï‚· Method 2:
Sentiment Analysis and Emotion Analysis
Sentiment Analysis is the process of identifying sentiment in text and analyse it. There are three types of sentiment analysis (Walaa Medhat, 2014):
- Document Level – Analyse the entire document as one topic and form an opinion or sentiment on the entire document
- Sentence Level – Analyse sentiment in each sentence
- Aspect Level – Analyse sentiment in respect to entities as you can have more than one aspect in a sentence for the same entity.
For this study, we are focusing our research on Sentence Level analysis using Semantic search.
Semantic Search:
Semantic search goes beyond the traditional keyword search by providing a meaning to a phrase and makes use of a wide range of resources to interpret the phrase and thus providing a more accurate result.
Some examples of semantic search in our daily lives:
- Conversational searches:
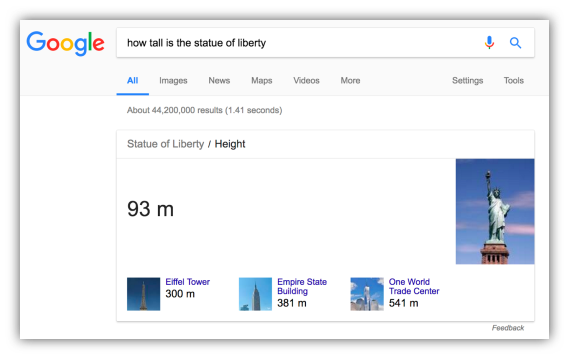
Figure 2: Conversational Search (Google, 2017)
- Auto Correct spelling mistakes:
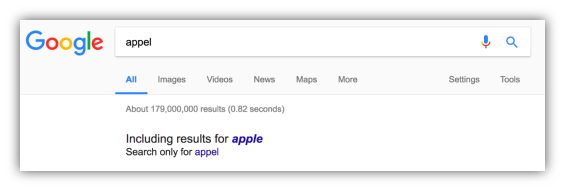
Figure 3: Auto Correct (Google, 2017)
- Display information in graphics format:
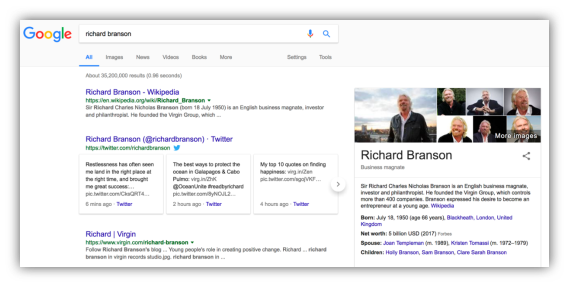
Figure 4: Information in graphics format (Google, 2017)
(Charu C. Aggarwal, 2012) outlines some challenges that are encountered when going through mining. These are the difficulty in recognising opinions, subjective phrases and emotions.
Opinion mining challenges.
When using semantic search method on a post one needs to understand that the post can contain all the following:
- Positive opinions “I like the computer I bought, it has a very clear screen”
- Negative opinions “however my wife thinks it’s too expensive”
- Different targets “The targets in the positive opinions relate to the computer and the screen whereas the targets in the negative opinions are the price”
- Different opinion holders “The positive opinions are mine however the negative opinions are of my wife”
Subjectivity mining challenges
Posts are also made up of objective and subjective comments. Subjective expressions like opinions, desire, assumptions amongst others may not contain opinions or may not express any positive or negative comments.
Emotions mining challenges
Emotions (love, joy, anger, fear, sadness, happiness and more) fall under a form of subjective expression. Sometimes emotions give no opinions in a phrase.
To observe the usefulness and ideal approach towards the analysis of social media related posts and messaging, a software algorithm was designed and partially developed to illustrate this scenario. The idea behind this software is to have the user write inside a textbox, mimicking an actual employee typing using a company machine, while the system monitors such text and acts per what it registers. Therefore, this tool will be presented as a standalone software/algorithm concept, emulating an actual activity of a possible employee, and as such must be adapted accordingly to make use of it in a real-life situation.
The basic principle of the solution proposed is made up of three modules:
- The key logger that monitors the user’s input at runtime and effects certain rules
- The keyword and semantic analysis on the data gathered
- The storage of produced analysis and log
The following flowchart outlines the lifecycle of said solution, followed by a detailed analysis of each component mentioned above, as well as possible ways on how it can be further enhanced to produce even more accurate results.
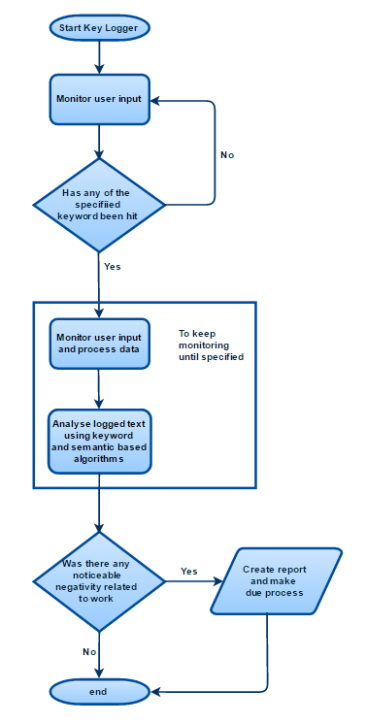
The flow of the proposed solution.
Created using draw.io (https://www.draw.io/)
Collecting and Processing Data
In this solution, key logging is used to monitor the data inputted by the user, which is a constant monitoring of the keystrokes registered by one’s activity, and registered as a stream of text ready to be dissected and analysed as required. The main advantage of using such a strategy is that data is collected and used in real-time, making it ideal for scenarios where an alarm (for example a negative post related to work) needs to be raised as quickly as possible to the relevant personnel, providing a detailed log of what the employee has typed (through the key logger) eliminating the need to monitor and access the relevant social media to check what has been posted.
Note: there are other strategies one can pursuit to monitor the user’s activity, such as firewall policies or general network surveillance, however in real-life situations such solutions can prove rather difficult to setup due to the expertise required; while web encryption and proxy services makes it even harder to effectively monitor the traffic generated by the users.
A key logger, even if effective, generates a lot of unneeded garbage beyond the scope of social media. For example, an employee working on his station would be constantly registering keystrokes which the logger is then adding them up to its own text stream. This could prove to be very problematic for three main reasons:
- The logger would begin to amass a significant amount of storage space, unless the key logger is given a limit of how much information it can hold and removing “old” data to make up space for the “new” data, but than some information can get permanently lost.
- The analysis of the text stream generated can be quite intensive, which can significantly affect the performance of the machine doing the analysis, especially when considering that the analysis is assumed to be processed on the user’s machine which most probably isn’t very well suited for such intensive work. Furthermore, following the previous point, the “garbage” log is being analysed too needlessly.
- The chances are that an employee would spend very little time on social media, thus logging and analysing the work-related activity is quite pointless for such a scope.
To overcome the above-mentioned issues, the proposed solution makes use of predefined social media trigger keywords i.e. a list of social media websites such as Facebook, Twitter, LinkedIn etc., where depending on such triggers being hit or not, the key logger will have two states, passive monitoring and active monitoring.
When the tool is running normally, the key logger is in a passive state keeping only the last 30 characters in its memory, without processing the stream. The only thing it does however, is to constantly check the stream read from the textbox in the tool against the trigger keywords, and if any of the keywords is found to have been registered then the key logger would go into active state. While in this state the key logger would increase its maximum capacity, and begin to log every keystroke while constantly analysing the feed. The key logger will go back to passive state when the predefined character limit is reached or enough time has passed.
Following this logic, only a set of keystrokes would be registered, reducing the chance of collecting and processing unneeded information while maintaining the workload and storage use of the machine to a minimum.
Note: in this approach once the key logger goes into active state, it is monitoring and analysing the feed at runtime locally, and this could prove to be quite intensive depending on the parameters set and the overall performance of the users’ machines. Organizations implementing this solution can opt to have the log analysed after the key loggers goes back into passive state and therefore analysing the data only once. Better yet, since the solution assumes that the key logger is analysing the data locally, instead the logs can be sent to a common server and be analysed as a scheduled task.
Once this data is captured through the key logger the feed can be processed by means of the methods discussed earlier (Method 1 and 2). Based on the outcome we store the data in our information system and align the data based on the organisation’s social policy.
Approaching data analysis using keyword and semantic methods
The designed software makes use of two different types of analysis algorithms, keyword based and semantic based, and are used together to try and cancel each other’s limitations and thus providing much more accurate results.
Keyword based analysis
The more traditional keyword analysis algorithm consists of having a list of keywords i.e. a predefined set of texts, and hit the data to be analysed against that list to determine whether any keywords have been hit and at what frequency. For example, having a text (representing the data) analysed against a list of negative texts (the keywords) would provide a set of statistical information which could be used to evaluate how negative the text is, which is conceptually what a social media monitoring tool should be trying to achieve.
However, the major flaw of this analysis algorithm within the context of social media monitoring, is that keyword based analysis is far too broad and prone to false alarms if not controlled. Having the data gathered from the key logger (therefore filtered to social media activity) analysed against a set of negative texts, the statistical information produced may not be relevant to the organizations’ interest. An employee could simply be posting a feed about how bad the weather is and how much s/he hates it, which the keyword analysis algorithm would recognize as negative and report accordingly.
In the proposed solution, the keyword based algorithm uses two different sets of keywords against the gathered data, with the aim to filter the batches of logged texts by relevance. The first set consists of a list of works related text, such as ‘work’, ‘job’, ‘company’, ‘[company name]’ etc. i.e. every keyword that could somehow link the user to the organization implementing the solution. In the second set, a list of keywords/texts associated with negativity are stored, such as ‘bored’, ‘unhappy’, ‘hate’, ‘dull’, ‘sick and tired’ etc.
When the data passed along through the key logger reaches the keyword analysis module, it would first check the log against the first set and therefore determine whether the data fed is of any relevance to work, and if not simply do nothing. On the other hand, if any of the keywords from the first set is hit, it means that the data inputted is relevant and therefore must be analysed further. In this case, the tool would analyse the entire log within the key logger (which is currently in an active state as described in the previous section) and extract the statistical information with regards to the second set.
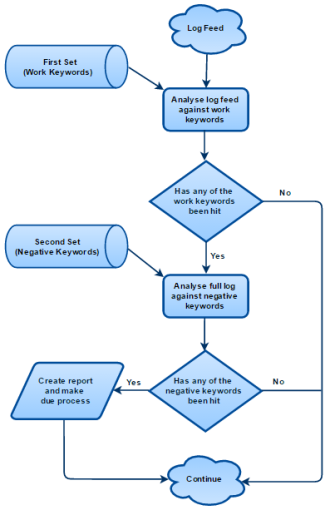
The flow of the full keyword based algorithm adapted in the tool
Created using draw.io (https://www.draw.io/)
Examples
Keywords to assume:
First Set (work): ‘WORK’, ‘JOB’
Second Set (negative): ‘BORED’, ‘UNHAPPY’, ‘SAD’, ‘HATE’, ‘DULL’, ‘TIRED’, ‘SICK AND TIRED’, ‘ANNOYED’, ‘FED UP’
Example 1:
|
Input |
Hate this weather, it’s severely effecting my mood. Constantly feeling tired and sad. |
|
Output |
None |
Example 2:
|
Input |
At work and bored. Wish I could find a better job, this one is just so annoying. |
|
Output |
BORED x 1 [full log] |
Example 3:
|
Input |
Never a dull moment at work. At the end of the day, the management brought in pizzas, fresh doughnuts and beer. In a couple of hours, the food was gone leaving everyone too tired to move. Got to love this company, always making sure their employees are never bored and unhappy. |
|
Output |
DULL x 1 TIRED x 1 BORED x 1 UNHAPPY x 1 [full log] |
From the examples above one can note a few limitations concerning the keyword based analysis algorithm.
In example 2 the logged text is alarming, which most probably would require the full attention of the responsible personnel, but due to the limited keywords, only a single piece of text was hit which would make the output seem not so alarming. Furthermore, the logged text had the word ‘annoying’ which in the negative keyword set is listed as ‘annoyed’, but still this was not captured. Therefore, this means that this algorithm is highly dependent on the keywords lists and possible deviations of each text.
In example 3 the output looks very alarming since the negative keywords list was hit 4 times, but the input is very positive. The algorithm was unable to take into consideration the context of how the negative words were used and simply counted the number of times they were encountered within the log, hence raising a false alarm.
To overcome such limitations, other algorithms must be used in conjunction with the keyword based, where in this solution the semantic based approach is used to compliment the algorithm and try to provide more accurate results.
Semantic based analysis
As explained in previous sections, semantic analysis introduces a certain degree of understanding when analysing a given text, and this is achieved by giving meaning to what it is fed. In this proposed software algorithm, this type of analysis is used to evaluate the sentiment and emotion behind the fed input, and therefore can determine whether the users’ work related activity on social media is negative or positive, which by extension may be able to overcome the limitations of keyword based approach.
Basic forms of semantic based algorithms used to analyse text in relation to sentiment and emotion, often providing a single value output denoted by a percentage, where 0% means that the text is absolutely negative and a 100% would indicate that without a doubt it is positive. However, semantic analysis is capable to go beyond a simple value, where some of which can produce a fully detailed report indicating the level of emotions for multiple types, such as anger, fearfulness and joy. The following is an example of such a report produced by the tool Tone Analyser offered by (Cloud, 2017).
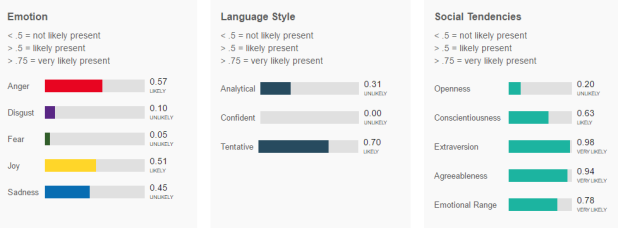
Example report of a semantic based algorithm offered by IBM Watson Developer Cloud
Applying such an algorithm which produces a very detailed report, may be well beyond the scope of monitoring work related activity on social media. In the end, what the proposed solution is trying to achieve is to detect negative activity which would harm said organizations’, that when detected, the log of that activity is passed along to the corresponding personnel with perhaps a brief report of the analysis.
Another drawback to be considered in this scenario, is that light weight semantic algorithms are much less intensive than algorithms which consider different types of emotions when analysing a text, and given that in the solution such an analysis will be triggered almost constantly, having a heavy algorithm being triggered would result in a very negative experience to said users. This is why in the proposed solution a lighter semantic analysis is considered, that is the API provided by (ParallelDots, 2017).
Note: one could argue that using a semantic analysis algorithm which produces a detailed report, could replace the entire algorithm which is using both the keyword based analysis and the light weight semantic based analysis. However, performance wise the latter would operate much smoother, and from a technical point of view considerably easier to setup.
Note: in the proposed solution, the semantic analysis will be conditional to whether the keyword based algorithm is triggered or not, and therefore subject to the filter which is detecting whether the activity on social media is related to work or not.
Examples using the sentiment analysis demo provided by (ParallelDots, 2017), which outputs single value percentages 0% being negative, while 100% being positive.
Example 1:
|
Input |
Hate this weather, it’s severely effecting my mood. Constantly feeling tired and sad. |
|
Output |
0% |
Example 2:
|
Input |
At work and bored. Wish I could find a better job, this one is just so annoying. |
|
Output |
6% |
Example 3:
|
Input |
Never a dull moment at work. At the end of the day, the management brought in pizzas, fresh doughnuts and beer. In a couple of hours, the food was gone leaving everyone too tired to move. Got to love this company, always making sure their employees are never bored and unhappy. |
|
Output |
79% |
Classifying severity based on score and frequency of words
Thus far, the algorithm detected negative activity on social media relating to work, using both keywords and semantic analysis. However, the term negative can be rather broad and it may be the case that the organization would not want to be alerted for every minor negative activity, since that will become counterproductive. As such the proposed algorithm has a threshold mechanism which determines whether to send in alerts or not.
The threshold settings are two. The minimum number of negative words the activity must contain, and the minimum percentage of negativity to be considered. Right after the key logger is finished monitoring the social media activity, if work related activity is logged, the system evaluates the log based on the threshold set by the administrators of the system, and proceed accordingly.
Using same parameters of previous example for keyword and semantic based approaches. The thresholds are set as follows: Minimum Keywords 1, Minimum Semantic Percentage 30%.
Example 1:
|
Input |
Hate this weather, it’s severely effecting my mood. Constantly feeling tired and sad. |
|
Output |
None (not work related) |
|
Alert |
No |
Example 2:
|
Input |
At work and bored. Wish I could find a better job, this one is just so annoying. |
|
Output |
Keywords hit: 1 Semantic: 6% |
|
Alert |
Yes |
Example 3:
|
Input |
Never a dull moment at work. At the end of the day, the management brought in pizzas, fresh doughnuts and beer. In a couple of hours, the food was gone leaving everyone too tired to move. Got to love this company, always making sure their employees are never bored and unhappy. |
|
Output |
Keywords hit: 4 Semantic: 79% |
|
Alert |
No |
Limitations of the current approach
The software that has been designed and partially developed as a concept for this paper needs to be further enhanced and developed to be able to be turned into a fully social media monitoring system in the work place environment. The proposed solution for this paper has several limitations that for the scope of this paper can be bypassed however for an effective implementation they would need to be addressed:
- The first limitation is that the system generates data which currently needs to be analysed by a person, even if different filters and threshold system are applied at key points during the process. The person in charge needs to monitor the text being captured and decide if this is of relevance to social media posting and if it’s of any harm to the organisation or its employees. This should be overcome with having a Decision Support System integrating with the data being collected by our monitoring software.
- Another limitation is that currently it will start capturing data once it detects certain keywords in the text. This should be coupled with the organisation firewall that once certain urls are detected the monitoring plugin kicks in and can stop monitoring once the social media sites are not active.
- When the software detects anything it currently does not stop the user from posting however it logs the information in the information system database for it to be analysed. This should be enhanced in a way that the user is alerted before posting the current post if it seems to violate the organizational social policy and preventing it from going viral.
Effective implementation & Future Enhancements
The software should be converted to be able to be installed as a plugin for browsers. Every time the browser loads up the plugin would activate and starts monitoring the urls that the user is loading within the browser. Once the plugin detects certain predefined urls of social media like Facebook, twitter etc. the plugin starts collecting data.
Companies would need to have certain policies in place
- A policy as to which are the approved browsers to be used within the company and effective restrictions should be in place to avoid users installing other browsers. This would enable the plugin to be installed on the most popular browsers.
- A policy on permissions which should not allow users to modify the browser plugins by disabling or uninstalling the monitoring plugin.
- A policy that informs users that computers at work are subject to monitoring and that any misuse of such equipment or using the mentioned equipment to harm the reputation of the company or its colleagues would engage in disciplinary actions.
Once data is collected the system will need to store this data in an Information System so that the collected data can be analysed and acted upon. Reports should be generated when certain thresholds are met.
Even though we would be monitoring any social media used from work computers there is a limitation to the proposed solution that is we will not be catering for Mobile devices, even if they are on our work network infrastructure. Even more mobile devices connected using a 4G data plan are not being monitored. For effective monitoring of mobile devices on the work infrastructure a different approach needs to be considered.
Other approaches that could cater for some limitations of this approach are real time search engines like google trends, and tools as per (Home, n.d.). These tools can be used when the organization needs some degree of off premises monitoring, they can give indications as to what is being said by the general public on social media which can be used as an indication or added information to what is being collected on premises.
Brod, C., 1984. Technostress: the human cost of the computer revolution. In: s.l.:Addison-Wesley.
Charu C. Aggarwal, C. Z., 2012. Mining Text Data. s.l.:Springer Science & Business Media.
Cloud, I. W. D., 2017. IBM Watson Developer Cloud. [Online]
Available at: https://tone-analyzer-demo.mybluemix.net
[Accessed 3 3 2017].
Dreher, S., 2014. Social media and the world of work. Corporate Communications: An International Journal, 19(4), pp. 344-356.
Eliane Bucher, C. F. &. A. S., 2013. The Stress potential of social media in the workplace. Information, Communication & Society, Volume 16:10, pp. 1639-1667.
Flynn, N., 2012. The SocialMedia Handbook: Policies and Best Practices to Effectively Manage Your Organization’s Social Media Presence, Posts, and Potential Risks. Pfeiffer, San Francisco, CA.
Google, 2017. Google Search Engine. [Online]
Available at: www.google.com
[Accessed 3 3 2017].
Home, H., n.d. Howards Home. [Online]
Available at: https://www.howardshome.com/
[Accessed 19 2 2017].
Leftheriotis, I. &. N. G. M., 2013. Using social media for work: Losing your time or improving your work?. Department of Informatics, Ionian University, Department of Computer and Information Science, Norwegian University of Science and Technology..
Lieber, L. D., 2011. Social Media in the Workplace – Proactive Protections for Employers.
ParallelDots, 2017. ParallelDots. [Online]
Available at: http://www.paralleldots.com/sentiment-analysis
[Accessed 3 3 2017].
Raghav Bali, D. S., 2016. R Machine Learning By Example. s.l.:s.n.
Smith, N. W. R. a. Z. C., 2010. Social Media Management Handbook: Everything You Need to Know to Get Social Media Working in Your Business. John Wiley & Sons Inc., Hoboken, NJ..
Trott, L., 2009. Social Media in the Workplace.
Turban, E. B. N. &. L. T.-P., 2011. Enterprise social networking opportunities, adoption, and risk mitigation. Journal of Organizational Computing and Electronic Commerce, pp. 21, 202-220.
Walaa Medhat, A. H. H. K., 2014. Sentiment analysis algorithms and applications: A survey. Ain Shams Engineering Journal, 5(4), pp. 1093-1113.
Zhang, X. C. X. G. D. V. X., 2016. Exploring the influence of social media on employee work performance. Internet Research, Volume 26, pp. 529-545.