Structural Integrity using SMA Revolutionary Technology
An Innovative Method for Improving the Structural Integrity using SMA Revolutionary Technology
The information and views set out in this [report/study/article/publication…] are those of the author(s) and do not necessarily reflect the official opinion of the European Union. Neither the European Union institutions and bodies nor any person acting on their behalf may be held responsible for the use which may be made of the information contained therein.
No third-party textual or artistic material is included in the publication without the copyright holder’s prior consent to further dissemination by other third parties.
Reproduction is authorised provided the source is acknowledged.
- Introduction
A novelty in Horizon 2020 is the Open Research Data Pilot which aims to improve and maximise access to and re-use of research data generated by funded projects [1.1]. Individual projects funded under Horizon 2020, which are not covered by the scope of the Pilot outlined above, may participate in the pilot on a voluntary basis. The project InnoSmart has opted-in the Open Research Data Pilot scheme, and is therefore obliged to provide a Data Management Plan (DMP) after the first 6 months as well as in the later stages of the project lifetime. The Open Research Data Pilot applies to two types of data:
- thedata, including associated metadataneeded to validate the results presented in scientific publications as soon as possible;
- otherdata, including associated metadata, as specified and within the deadlines laid down in the data management plan – that is, according to the individual judgement by each project.
The purpose of the DMP is to provide an analysis of the main elements of the data management policy that will be used by the applicants with regard to all the datasets that will be generated by the project. The DMP is not a fixed document, but evolves during the lifespan of the project. The DMP should address the points below on a dataset by dataset basis and should reflect the current status of reflection within the consortium about the data that will be produced [1.2]:
- Datasetreferenceandname:Identifier for the data set to be produced.
- Datasetdescription:Description of the data that will be generated or collected, its origin (in case it is collected), nature and scale and to whom it could be useful, and whether it underpins a scientific publication. Information on the existence (or not) of similar data and the possibilities for integration and reuse.
- Standardsandmetadata:Reference to existing suitable standards of the discipline. If these do not exist, an outline on how and what metadata will be created. Good data organisation is necessary to prevent duplication of files and other errors, and consistent naming and versioning procedures ensure that the correct data can be retrieved simply, especially if multiple people are working on the same files. Try to:
- Give folders clear names relating to their area/subject, not names of researchers.
- Keep folder and file names short and concise; avoid using special characters or spaces, as not all software can handle them.
- If dates are important, use the standard format YYYY-MM-DD at the start of the file name.
- Datasharing:Description of how data will be shared, including access procedures, embargo periods (if any), outlines of technical mechanisms for dissemination and necessary software and other tools for enabling re-use, and definition of whether access will be widely open or restricted to specific groups. Identification of the repository where data will be stored, if already existing and identified, indicating in particular the type of repository (institutional, standard repository for the discipline, etc.). In case the dataset cannot be shared, the reasons for this should be mentioned (e.g. ethical, rules of personal data, intellectual property, commercial, privacy-related, security- related).
- Archivingandpreservation(including storage and backup): Description of the procedures that will be put in place for long-term preservation of the data. Indication of how long the data should be preserved, what is its approximated end volume, what the associated costs are and how these are planned to be covered.
It should also be noted that participating in the Pilot does not necessarily mean opening up all research data. The focus of the Pilot is on encouraging good data management as an essential element of research best practice. Projects participating in the Pilot must comply with the following:
- Participating projects are required to deposit the research data described above, preferably into a research data repository. ‘Research data repositories’ are online archives for research data. They can be subject-based/thematic, institutional or centralised.
- As far as possible, projects must then take measures to enable for third parties to access, mine, exploit, reproduce and disseminate (free of charge for any user) this research.
At the same time, projects should provide information via the chosen repository about tools and instruments at the disposal of the beneficiaries and necessary for validating the results, for instance specialised software or software code, algorithms, analysis protocols, etc. Where possible, they should provide the tools and instruments themselves.
The project InnoSmart is divided into seven work packages (WP1-WP7) where the majority of them include data gathering, processing and/or manipulation. The gathered data will be derived mainly from development and testing of the Smart Memory Alloys (SMA’s) within laboratory conditions, testing of coating alloy composition and coating characteristics,  laser profilometry, numerical structural assessment and prognostic  models, and validation of mapping and numerical assessment software.
- Data derived from WP2: Development of the SMA elements
- Data set reference and name
The dataset is related to the development of the Smart Memory Alloys (SMA) and the laboratory trials for verification reasons. The reference name for this dataset should be used as SMALabTrials.
- Data set description
This dataset will be derived from the work package WP2, Â mainly Task 2.2: Laboratory trials for verification reasons.
In order to determine the physical nature of the SMA elements for the coating application, the properties of SMA materials will be investigated to ensure the sustainment of their thermomechanical properties due to processing. The SMAs will be trained for obtaining a determined geometry and laboratory trials will be conducted to samples, such as plates where the physical nature of the SMAs will be tested for its functionality.
The data will be reported for the processing conditions, the thermo-mechanical properties of the SMA plates, and their functionality.
- Standards and metadata
The metadata for each data class will comprise the following:
- SMA processing conditions (processing temperature, atmosphere, etc.)
- Mechanical properties (hardness, toughness, tensile strength, elastic moduli, etc.)
- Physical properties (electrical resitivity, sound velocities, density, thermal conductivity, etc.)
- Thermomechanical characteristics in response to temperature (IR thermography, etc.)
- Microstructural characterization (Optical microscopy, electron  microscopy, etc.)
2.3.1. Fileandfoldernames
The proposed folder names should include date, dataset name, dataset specifics, and dataset version. DateStamp_datasetName_datasetSpecifics_datasetVersion (e.g. “2015_12_09_SMALabTrial_Thermo_v01”). Each file name inside a folder should include the all details of a belonging folder name, and any additional specifics of the file related to operating or environmental conditions.
Each folder will contain a readme.txt file containing metadata information and description of the dataset.
- Data sharing
The data product will be updated in line with the experimental tests. The date of the update will be included in the data file and will be part of the data file name. During the project lifetime the data will be shared through publications in scientific journals or presentations in technical conferences.
During the project lifetime the data will be shared publicly only after the patents have been submitted or published on scientific journals, in order not to jeopardise the project objectives and deliverables.
- Datasharingrepository
The dataset will be shared on Zenodo research data sharing platform (http://www.zenodo.org/) during the project lifetime as well as after. Zenodo enables researchers, scientists, EU projects and institutions to:
- easily share the long tail of research results in a wide variety of formats including text, spreadsheets, audio, video, and images across all fields of science,
- display their research results and receive credit by making the research results citable and integrating them into existing reporting lines to funding agencies like the European Commission, and
- easily access and reuse shared research results.
- Licensing
The dataset will be made publicly available under Creative Commons Non- commercial Share-alike license version 4.0 – CC BY-NC-SA 4.0 – http://creativecommons.org/licenses/by-nc-sa/4.0/. The selected license enables anyone to freely
- share – copy and redistribute the material in any medium or format, and
- adapt – remix, transform, and build upon the material.
The licensor cannot revoke these freedoms as long as one follows the license terms. The following terms must be acknowledged:
- Attribution – one must give appropriate credit, provide a link to the license, and indicate if changes were made. One may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- NonCommercial – One may not use the material for commercial purposes.
- ShareAlike – If one remixes, transforms, or builds upon the material, one must distribute the contributions under the same license as the original.
- Archiving and preservation (including storage and backup)
The dataset will be made publicly available for long-term using Zenodo research data sharing platform (http://www.zenodo.org/) or alternatively Cranfield University internal storage capabilities. Both services enable data sharing free of charge so we are not expecting any additional costs after the project lifetime.
Our intent is to make the generated data available for use by academic community and industries available for five years.
- Data derived from WP3: Creation and experimental investigation of the SMA coating
- Data set reference and name
The dataset is related to the coating alloy composition, coating characteristics and properties data. The reference for this dataset should be used as CoatingAlloy.
- Data set description
This dataset will be derived from the work package WP3, mainly tasks Task 3.2: Experimental investigation of the coating, and Task 3.3: Testing of the coating’s abilities.
There are several databases for engineering materials but most of these databases cover conventional materials like plastics and steels. For SMA on the other hand only a limited number of alloys is of engineering interest which properties and their parameter dependence have to be handled in order to make the database useful. During this project different coating alloy compositions as well as different coating deposition techniques will be tested.
Coating characteristics and properties data will contain coating characteristics and properties as outcomes of: phase change properties determination, mechanical and microstructural analysis, adhesion tests, anticorrosive properties evaluations.
- Standards and metadata
Metadata for each data class will comprise the following:
- Coating characteristics (alloy composition, thickness, deposition technique etc.).
- Phase change properties (resistivity, differential scanning calorimetry)
- Mechanical (tensile properties, hardness and so on..)
- Microstructural (Electron microscopy: SEM/EDS, TEM- X-ray diffraction)
- Adhesion tests ( bend test)
- Anticorrosiveproperties(Linearsweepvoltammetry,electrochemical impedance spectroscopy).
Metadata will contain descriptions of the data sources, test parameters and procedures, specimen information, results etc.
All properties data for each coating with defined composition will be presented with testing parameters such as temperatures, number of cycles, etc. Thermomechanical training, transformation temperatures, compositions will be also available.
3.3.1. Fileandfoldernames
The data will be saved as text file according to ASCII format. XML format for our metadata will be chosen in order to provide compatibility with international standards (xml format). The data will be collected as shown in Figure 3.1:
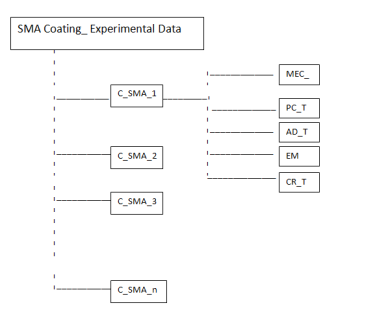
Figure3.1:Dataorganisation
The proposed folder names should include date, dataset name, dataset specifics, and dataset version. DateStamp_datasetName_datasetSpecifics_datasetVersion (e.g. “2015_12_09_coatingAlloy_phaseChange_v01”). The dataset will be organized into a specified folder, which will be subdivided in different subfolder named C_SMA_1, C_SMA_2… C_SMA_n (where ncorresponds to the number of the coating sample). Mechanical, phase change, adhesion, microstructural and corrosion resistance properties will be evaluated and the outcomes of each test will be included in the associated subfolders, MEC_, PC_T, AD_T, EM, CR_T respectively.
Each file name inside a folder should include the all details of a belonging folder name, and any additional specifics of the file related to operating or environmental conditions. Each folder will contain a readme.txt file containing metadata information and description of the dataset.
- Data sharing
Research data will be will be open access after publication of manuscripts based on the data we collect. The shared data are expected to be of interest to scientists as well as to the coating industry. Data generated under the project will be disseminated in accordance to the Consortium Agreement. Raw data will be maintained on hard drive and made available on request.
- Datasharingrepository
The dataset will be shared on Zenodo research data sharing platform (http://www.zenodo.org/) during the project lifetime as well as after. Zenodo enables researchers, scientists, EU projects and institutions to:
- easily share the long tail of research results in a wide variety of formats including text, spreadsheets, audio, video, and images across all fields of science,
- display their research results and receive credit by making the research results citable and integrating them into existing reporting lines to funding agencies like the European Commission, and
- easily access and reuse shared research results.
During the project lifetime the data will be shared publicly only after the patents have been submitted or published on scientific journals, in order not to jeopardise the project objectives and deliverables.
- Licensing
The dataset will be made publicly available under Creative Commons Non- commercial Share-alike license version 4.0 – CC BY-NC-SA 4.0 – http://creativecommons.org/licenses/by-nc-sa/4.0/. The selected license enables anyone to freely
- share – copy and redistribute the material in any medium or format, and
- adapt – remix, transform, and build upon the material.
The licensor cannot revoke these freedoms as long as one follows the license terms. The following terms must be acknowledged:
- Attribution – one must give appropriate credit, provide a link to the license, and indicate if changes were made. One may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- NonCommercial – One may not use the material for commercial purposes.
- ShareAlike – If one remixes, transforms, or builds upon the material, one must distribute the contributions under the same license as the original.
- Archiving and preservation (including storage and backup)
The dataset will be made publicly available for long-term using Zenodo research data sharing platform (http://www.zenodo.org/) or alternatively Cranfield University internal storage capabilities. Both services enable data sharing free of charge so we are not expecting any additional costs after the project lifetime.
The data product will be updated in line with the experimental tests. The date of the update will be included in the data file and will be part of the data file name. The daily and monthly backups of the data files will be retained in an archive system.
Our intent is to make the generated data available for use by academic community and industries available for five years.
- Data derived from WP4: Design, development and manufacture of the manipulating device, and WP6: System integration, laboratory and field trials
- Data set reference and name
The dataset is related to the design of the Laser Profilometer, its testing and validation, as well as testing of the prototype under laboratory conditions or using the actual aircraft. The reference for this dataset should be used as LPValid.
In addition, the dataset is related to the prototype design, its testing and validation within laboratory and field conditions. The reference for this dataset should be used as ProtoValid.
- Data set description
This dataset will be derived from the work package WP4, mainly Task 4.2.: Manufacture manipulating device including LP, and Task 4.3. Test and validate manipulating device. Additionally, the same dataset will be derived from the work package related to prototype testing Task 6.2. Laboratory testing, and Task 6.3. Trial on actual metallic structures.
LP will capture the 3D profiles of an object by laser projection techniques, which is a method to generate sinusoidal waves (oscillations) or optical patterns by a display within the projector and direct these waves on the surface. The interaction of the waves on a surface causes alternating lines of dark and light bands called as fringes. Fringe patterns of coated surfaces tend to resemble non-stationary 3D signals, with intensity along z axis and pixels represent the length. The LP data will be used for fringe pattern analysis, which has recently seen significant interest due to its widespread application in engineering.
- Standards and metadata
The metadata for each data class will comprise the following:
- Detailed condition of the analysed specimen (i.e. faultfree, damaged, damage size, etc.)
- Type of material and type of coating
4.3.1. Fileandfoldernames
The proposed folder names should include date, dataset name, dataset specifics, and dataset version. DateStamp_datasetName_datasetSpecifics_datasetVersion (e.g. “2015_12_09_LPValid_Condition_v01”). Each file name inside a folder should
include the all details of a belonging folder name, and any additional specifics of the file related to operating or environmental conditions.
Each folder will contain a readme.txt file containing metadata information and description of the dataset.
- Data sharing
The data product will be updated in line with the experimental tests. The date of the update will be included in the data file and will be part of the data file name in terms of date and version.
- Datasharingrepository
The dataset will be shared on Zenodo research data sharing platform (http://www.zenodo.org/) during the project lifetime as well as after. Zenodo enables researchers, scientists, EU projects and institutions to:
- easily share the long tail of research results in a wide variety of formats including text, spreadsheets, audio, video, and images across all fields of science,
- display their research results and receive credit by making the research results citable and integrating them into existing reporting lines to funding agencies like the European Commission, and
- easily access and reuse shared research results.
During the project lifetime the data will be shared publicly only after the patents have been submitted or published on scientific journals, in order not to jeopardise the project objectives and deliverables.
- Licensing
The dataset will be made publicly available under Creative Commons Non- commercial Share-alike license version 4.0 – CC BY-NC-SA 4.0 – http://creativecommons.org/licenses/by-nc-sa/4.0/. The selected license enables anyone to freely
- share – copy and redistribute the material in any medium or format, and
- adapt – remix, transform, and build upon the material.
The licensor cannot revoke these freedoms as long as one follows the license terms. The following terms must be acknowledged:
- Attribution – one must give appropriate credit, provide a link to the license, and indicate if changes were made. One may do so in any reasonable
manner, but not in any way that suggests the licensor endorses you or your use.
- NonCommercial – One may not use the material for commercial purposes.
- ShareAlike – If one remixes, transforms, or builds upon the material, one must distribute the contributions under the same license as the original.
- Archiving and preservation (including storage and backup)
The dataset will be made publicly available for long-term using Zenodo research data sharing platform (http://www.zenodo.org/) or alternatively Cranfield University internal storage capabilities. Both services enable data sharing free of charge so we are not expecting any additional costs after the project lifetime.
Our intent is to make the generated data available for use by academic community and industries available for five years.
- Data derived from Package WP5: Development of software for mapping and numerical deformation assessment
- Data set reference and name
Within the WP5 the following two data sets are expected to be derived:
- StrucAssess– Numerical structural assessment and prognostic models, and
- ValidMap– Validate mapping and numerical assessment software.
However, in a later stage of the InnoSMART project this document will be enriched and if necessary additional data sets might be included.
- Data set description
- Numericalstructuralassessmentandprognosticmodels
The following data set refers to the work that will be carried out in Tasks 5.2 and 5.3. This work involves the structural assessment of a component and it expected to be based on the following:
Numerical Structural Assessment
- Finite Element (FE) Method – FE Software
- Non – Linear Analysis (for allowing large displacements)
- Geometric characteristics of the structural component
- Geometric characteristics of the crack
- Mechanical Material Properties
- Boundary Conditions
- Loading Conditions
- Scripting code (macro-routine)
The analysis will be carried out using the Finite Element Method using a respective software that can satisfy the project’s needs. Within the FE software a non-linear analysis will be executed for considering large displacement. The last is essential particularly in the cases where flaws, such as crack exist. The geometric characteristics of the structural component with the crack will be generated and eventually an FE model will be developed. Additionally, inputs regarding the material models, the boundary and the loading conditions will be required. It is worth mentioning that all these aspects of the component will be defined through a macro routine comprised by the scripting language of the FE software. This will allow the parametric definition of all variables of the analysis problem. To this end an easy insertion of changing the input data can be accomplished.
Prognostic Models
- Post processing capabilities of the FE software
- Fracture mechanics
- Failure criteria for metallic materials based on Damage Tolerance (DT)
- Residual strength of the component
- Remaining life of the component
- Scripting code (macro-routine)
The outcome of the fore mentioned numerical analysis will be processed according to the post-processing capabilities of the FE software. Therefore, fracture mechanics capabilities of the FE software need to be available to ensure accuracy and validity for the results. Additionally, appropriate failure criteria are intended to be employed based on DT for assessing the residual strength of the component. In case that fatigue analysis is carried out; conclusions regarding the remaining life of the component will be also available. Once again, a macro routine will be written for executing the assessment of the component and produce clearly results regarding the status of the investigated component (continue to operate, repair or discard/substitute).
- Validatemappingandnumericalassessmentsoftware
The following data set refer to the work that will be carried out in Tasks 5.5. This work involves the validation of mapping and numerical assessment software and it expected ideally to be carried through experimental trials. Therefore, this task will be based on the following:
Validation of Mapping Software
- Experimental apparatus
- Test samples (size of coupons) with known defects (size and location)
- Sensors for measuring deformations
- Data acquisition system
Validation of Numerical Assessment Software
- All mentioned in the above list
- Algorithm for comparing the numerical with the experimental results
The validation of the mapping and the numerical structural assessment software can be possibly carried out through a series of experimental trials in cracked coupons where the size and the location of the damage are known. Appropriate experimental apparatus can potentially be utilised for conducting the mechanical tests to the samples. Employing appropriate sensors or optical methods the deformations/strain will be measured with the use of a data acquisition system. Eventually, a representative deformation field will be available for comparison and validation purposes.
The same procedure can potentially be used for validating the numerical structural analysis. The mechanical tests can be conducted up to failure for the sample. To this end pieces of information regarding the actual status of the residual strength of the sample will be found. A possible useful output is the load where unstable crack propagation occurs. Finally, an algorithm can be developed for accurately performing the comparison between the numerical and experimental results. Ultimately, conclusions regarding the validity of the numerical assessment software will be drawn.
- Standards and metadata
Regarding Tasks 5.2, 5.3 and 5.5 no standards will be used, since there are no relevant standards for the actions that will be taken. At this initial stage of the project where no actual results/output have been generated from Task 5.2, 5.3 and 5.5 no information regarding possible metadata can be documented hereafter. It is expected to have more information in an updated version of this document.
- Fileandfoldernames
The proposed folder names should include date, dataset name, dataset specifics, and dataset version. DateStamp_datasetName_datasetSpecifics_datasetVersion (e.g. “2015_12_09_StrucAssess_Fracture_v01”). Each file name inside a folder should include the all details of a belonging folder name, and any additional specifics of the file related to operating or environmental conditions.
Each folder will contain a readme.txt file containing metadata information and description of the dataset.
- Data sharing
The data that will be produced as can be seen from the description above will allow the partners to make several publications in high impact journals. The publications arise from the project will be open access in order to be exploit by not only the academic community by from the industry as this is the main goal of the consortium.
- Datasharingrepository
The dataset will be shared on Zenodo research data sharing platform (http://www.zenodo.org/) during the project lifetime as well as after. Zenodo enables researchers, scientists, EU projects and institutions to:
- easily share the long tail of research results in a wide variety of formats including text, spreadsheets, audio, video, and images across all fields of science,
- display their research results and receive credit by making the research results citable and integrating them into existing reporting lines to funding agencies like the European Commission, and
- easily access and reuse shared research results.
During the project lifetime the data will be shared publicly only after the patents have been submitted or published on scientific journals, in order not to jeopardise the project objectives and deliverables.
- Licensing
The dataset will be made publicly available under Creative Commons Non- commercial Share-alike license version 4.0 – CC BY-NC-SA 4.0 – http://creativecommons.org/licenses/by-nc-sa/4.0/. The selected license enables anyone to freely
- share – copy and redistribute the material in any medium or format, and
- adapt – remix, transform, and build upon the material.
The licensor cannot revoke these freedoms as long as one follows the license terms. The following terms must be acknowledged:
- Attribution – one must give appropriate credit, provide a link to the license, and indicate if changes were made. One may do so in any reasonable manner, but not in any way that suggests the licensor endorses you or your use.
- NonCommercial – One may not use the material for commercial purposes.
- ShareAlike – If one remixes, transforms, or builds upon the material, one must distribute the contributions under the same license as the original.
- Archiving and preservation (including storage and backup)
The dataset will be made publicly available for long-term using Zenodo research data sharing platform (http://www.zenodo.org/) or alternatively Cranfield University internal storage capabilities. Both services enable data sharing free of charge so we are not expecting any additional costs after the project lifetime.
Our intent is to make the generated data available for use by academic community and industries available for five years.
- References
[1.1] http://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pi lot/h2020-hi-oa-pilot-guide_en.pdf
[1.2] http://ec.europa.eu/research/participants/data/ref/h2020/grants_manual/hi/oa_pi lot/h2020-hi-oa-data-mgt_en.pdf