Using Data Wrangling and Gemms for Metadata Management
Abstract–Data lakes are gestated as to be a unified data repository for an enterprise to store data without subjecting that data to any of the constraints while it is being dumped in to the repository. The main idea of this paper is to explain about the different processes involving curating of data in the data lake which facilitates and helps wide range of people other than IT staffs in an enterprise or organization
Keywords-  Data Lake  ;  Data Wrangling ; GEMMS
I.INTRODUCTION
     In the current scenario, data is seen as a valuable asset for an enterprise or organization. Many of the organizations are now planning to provide with personalized or individual services to it’s customers and this strategy can achieved with the help of data lakes. Data wrangling refers to the process which starts right from data creation till it’s storage into the lakes. James Dixon, the originator of terminology explains the difference between data mart, datawarehouse and data lakes as, If data lake is assumed to be a large water body, where in the water can be used for any purpose then data mart is a store which has bottled drinking water and datawarehouse is marked as a single bottle of water (O’Leary,2014). Even though data warehouses, data marts,databases are used for storing data, but data lakes provides with some additional features and even data lakes can work in accordance with all of the above ones.
       Data lakes address the daunting challenge : “how to make an easy use of highly diverse data and provide knowledge?” Huge quantity of data is available,but most of the times data is stored in information silos with or without connections between these data. If any clear insight is to be derived then data in t he silos is to be integrated.(Hai , et al. 2016)
       Instead of performing the traditional methods of data warehousing for data management likewise transforming ,cleaning and then storing into repository, here in the data is stored in original format and as required the data is processed in data lake. By implementing in such approach data integrity is achieved (Quix, et al.2016)
        As per the present situation in the big data world, evaluating large data sets with their quality & cleaning them which are of various types has become a challenging task and data lakes can help in achieving them (Farid, et al. 2016)
II. LITERATURE REVIEW
For easing the process of data curating there are two methodologies namely Data wrangling and GEMMS which helps in achieving the curation process.
A. Data Wrangling
B. GEMMS
A. Data Wrangling
 Data Curation is in use to mainly specify the required necessary steps in order to maintain and utilize data during it’s life cycle for future and current users
Digital curation involves following steps
- The data is selected and appraised by archivists and creators of that data
- Evolving the provisions of intellectual access, storage which are redundant, transformation of data and then committing the specific data for long term usage
- Developing digital repositories which are trustworthy and durable
- Usage standard file formats and data encoding concepts
- Giving knowledge regarding the repositories to the individuals who are working with those repositories in order to make curation efforts successful(Terrizzano, et al.2015)
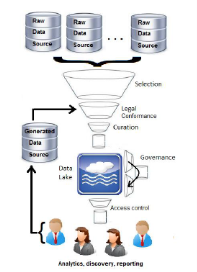
Figure 1: Data Wrangling Process Overview(Terrizzano, et al.2015)
 In the above figure it represents a number of challenges inherent in creating, filling, maintaining, and governing a curated data lake, a set of processes that collectively define the actions of data wrangling
 Different steps involved in the data wrangling process are:
1. Procuring Data: It the first step of data wrangling process, Herein the required metadata and data is gathered so as it can be included into the data lakes(Terrizzano, et al.2015)
2. Vetting data for licensing and legal use:
After the data procurement is done, then the terms and conditions are determined so as the data can be licensed (Terrizzano, et al.2015)
3. Obtaining and Describing Data:
Once the licensing relating to the selected data is agreed upon, the next task is loading the data from source to data lake and the presence of data alone cannot serve the needs, data scientist working on that data should find out that data to be useful so that it can be used to derive useful information out of it. (Terrizzano, et al.2015)
4. Grooming and Provisioning Data:
Data obtained in its raw form is often not suitable for direct use by analytics. We use the term data grooming to describe the step-by-step process through which raw data is made consumable by analytic applications.
    During Data Provisioning, we now focus on getting data into the data lake. We now turn to the means and policies by which consumers take data out of the data lake, a process we refer to as data provisioning (Terrizzano, et al.2015)
5. Preserving Data: This is the final step of the data curation process isManaging a data lake which requires attention to maintenance issues such as staleness, expiration, decommissions and renewals, as well as the logistical issues of the supporting technologies (assuring uptime access to data, sufficient storage space, etc.). (Terrizzano, et al.2015)
B. GEMMS(Generic and Extensible Metadata Management System)
Generic and Extensible Metadata Management System (GEMMS) which(i) extracts data and metadata from heterogeneous sources,(ii)stores the metadata in an extensible metamodel, (iii)enables the annotation of the metadata with semantic information, and (iv)provides basic querying support (Quix, et al.2016)
     We divide the functionalities of GEMMS into three parts: (i)metadata extraction,(ii) transformation of the metadata to the metadata model and (iii) metadata storage in a data store
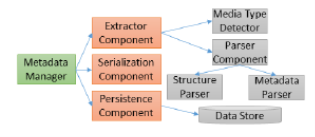
Figure 2: Overview of GEMMS system architecture
(Quix, et al.2016)
(i). The Metadata Manager invokes the functions of the other modules and controls the whole ingestion process. It is usually invoked at the arrival of new files, either explicitly by a user using the command-line interface or by a regularly scheduled job
(ii). With the assistance of the Media Type Detector and the Parser Component, the Extractor Component extracts the metadata from files. Given an input file, the Media Type Detector detects its format, returns the information to the Extractor Component, which instantiates a corresponding Parser Component.
(iii). The media type detector is based to a large degree on Apache Tika, a framework for the detection of file types and extraction of metadata and data for a large number of file types. Media type detection will first investigate the file extension, but as this might be too generic
(iv). When the type of input file is known, the Parser Component can read the inner structure of the file and extract all the needed metadata
(v). The Persistence Component accesses the data storage available for GEMMS. The Serialization Component performs the transformation between models and storage formats (Quix, et al.2016).
Evaluation of GEMMS System:
The goal of evaluation had two parts and GEMMS satisfies these to a major extent
(i). GEMMS as a framework is actually useful, extensible, and flexible and that it reduces the effort for metadata management in data lakes
(ii). GEMMS system can be applied to a system having large number of files (Quix, et al.2016)
II. CONCLUSIONS
Data lakes is getting hotter in enterprise IT architecture.
However, the company should decide what kind of data lakes
they need based on the current data process systems. Data lakes have its own assumptions and maturity growing framework. The IT leader in large organization should pay attention to the data lakes and figure out their own way for implementing these new IT technologies in their organization (Fang,2015)
       In this paper, we discussed about Data wrangling , which helps in design, implementation and maintaining the data. Along side the metadata management aspects using GEMMS, which efficiently eases the process and giving the evaluation how GEMMS stays on top in the meta data management in the
data lakes which helps large organisation in managing the data if that organisation is implementing Data Lakes
REFERENCES
- O’Leary, D.E., 2014. Embedding AI and crowdsourcing in the big data lake. IEEE Intelligent Systems, 29(5), pp.70-73.
- Hai, R., Geisler, S. and Quix, C., 2016, June. Constance: An intelligent data lake system. In Proceedings of the 2016 International Conference on Management of Data (pp. 2097-2100). ACM.
- Quix, C., Hai, R. and Vatov, I., 2016. Gemms: A generic and extensible metadata management system for data lakes. In CAiSE forum.
- Farid, M., Roatis, A., Ilyas, I.F., Hoffmann, H.F. and Chu, X., 2016, June. CLAMS: bringing quality to data lakes. In Proceedings of the 2016 International Conference on Management of Data (pp. 2089-2092). ACM.
- Terrizzano, I., Schwarz, P.M., Roth, M. and Colino, J.E., 2015. Data Wrangling: The Challenging Yourney from the Wild to the Lake. In CIDR.